ETL Testing
Everything you need to know to be successful in
automating your ETL testing & improving your
data quality
ETL Testing
Everything you need to know about ETL Testing to be successful in improving your data quality.
CONTENTS
- What does ETL stand for?
- Why perform an ETL?
- What is a Data Warehouse?
- What is Big Data?
- Why deal with all this data?
- What is Business Intelligence software?
- Typical Data Architecture
- How does the ETL process work?
- Who is involved in the ETL process?
- Why perform ETL Testing?
- How does ETL Testing work?
- What is Sampling?
- What is a Minus Query?
- Tools, Utilities and Frameworks
- Commercial Software
- The Bottom Line

What does ETL stand for?
ETL = Extract, Transform, Load
According to Wikipedia, “Extract, Transform, Load (ETL) is the general procedure of copying data from one or more data sources into a destination system which represents the data differently from the source(s). The ETL process is often used in data warehousing.
- Data extraction involves extracting data from homogeneous or heterogeneous sources
- Data transformation processes data by cleaning and transforming them into a proper storage format/structure for the purposes of querying and analysis
- Data loading describes the insertion of data into the target data store, data mart, data lake or data warehouse.
A properly designed ETL system extracts data from the source systems, enforces data quality and consistency standards, conforms data so that separate sources can be used together, and finally delivers data in a presentation-ready format.“
(source: Wikipedia https://en.wikipedia.org/wiki/Extract,_transform,_load)

ETL vs ELT
As stated above, ETL = Extract, Transform, Load. ELT, on the other hand = Extract, Load, Transform.
According to IBM, “the most obvious difference between ETL and ELT is the difference in order of operations. ELT copies or exports the data from the source locations, but instead of loading it to a staging area for transformation, it loads the raw data directly to the target data store to be transformed as needed.
While both processes leverage a variety of data repositories, such as databases, data warehouses, and data lakes, each process has its advantages and disadvantages. ELT is particularly useful for high-volume, unstructured datasets as loading can occur directly from the source. ELT can be more ideal for big data management since it doesn’t need much upfront planning for data extraction and storage. The ETL process, on the other hand, requires more definition at the onset. Specific data points need to be identified for extraction along with any potential “keys” to integrate across disparate source systems. Even after that work is completed, the business rules for data transformations need to be constructed. While ELT has become increasingly more popular with the adoption of cloud databases, it has its own disadvantages for being the newer process, meaning that best practices are still being established.”
(source: IBM https://www.ibm.com/cloud/learn/etl)
Why perform an ETL?
To load a data warehouse or data mart regularly (daily/weekly) so that it can serve its purpose of facilitating business analysis. Or move data from files, xml or other sources to a big data lake, data warehouse or data mart.
What is a Data Warehouse?
A data warehouse is:
- Typically a relational database that is designed for query and analysis rather than for transaction processing
- A place where historical data is stored for archival, analysis and security purposes.
- contains either raw data or formatted data
- combines data from multiple sources (i.e. Sales data, salaries, operational data , human resource data, inventory data, web logs, social networks, Internet text and docs, other)
Data Mart
A data mart is a subset of a data warehouse that has the same characteristics but is usually smaller and is focused on the data for one division or one workgroup within an enterprise.
What is Big Data?
Big Data is defined as too much volume, velocity and variability to work on normal database architectures. Typically, Hadoop is the architecture used for big data lakes. Hadoop is an Apache open source project that develops software for scalable, distributed computing.
Hadoop is:
- a framework for distributed processing of large data sets across clusters of computers using simple programming models
- deals with complexities of high volume, velocity and variety of data
- scales up from single servers to 1,000’s of machines, each offering local computation and storage
- detects and handles failures at the application layer
Why deal with all this data?
- The benefit to moving data from sources (files, databases, xml, web services, mainframes, external feeds, etc.) is to have it in an optimized target data store to analyze, look for trends and make strategic and tactical decisions based on this data.
- To analyze the data, business intelligence software is connected to the data warehouse or data mart.
What is Business Intelligence (BI) software?
Business Intelligence (BI) software is used in identifying, digging-out, and analyzing business data. BI provides simple access to data which can be used in day-to-day operations and integrates data into logical business areas. It also provides historical, current and predictive views of business operations. BI is made up of several related activities, including data mining, online analytical processing, querying and reporting.
C‑level executives and managers use BI & Analytics software to make critical business decisions based on the underlying data.
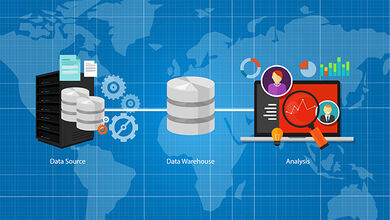
Typical Data Architecture
Below is a picture that demonstrates a typical data architecture where data may be moving in the following manner:
- From databases, Excel, json, web services or mainframe into a big data lake to a data warehouse to a data mart and being interpreted through business intelligence (BI) solutions
- As a data migration from a data warehouse on premises to a data warehouse in the cloud and interpreted through BI solutions
- From an enterprise application (finance, trading, sales, ERP, research, etc.) into a data warehouse and interpreted through BI solutions

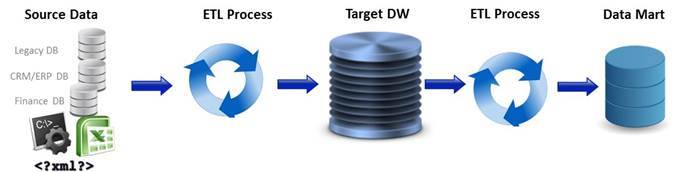
How does the ETL process work?
Extract – ETL developers extract data from one or more systems and/or files and copy it into the data warehouse
Transform – They remove inconsistencies, assemble to a common format, adding missing fields, summarizing detailed data and deriving new fields to store calculated data. Most data in an ETL process is not transformed (about 80% based on a poll of data architects).
Load – They map the data to the proper tables and columns, transform and/or load it into the data warehouse.

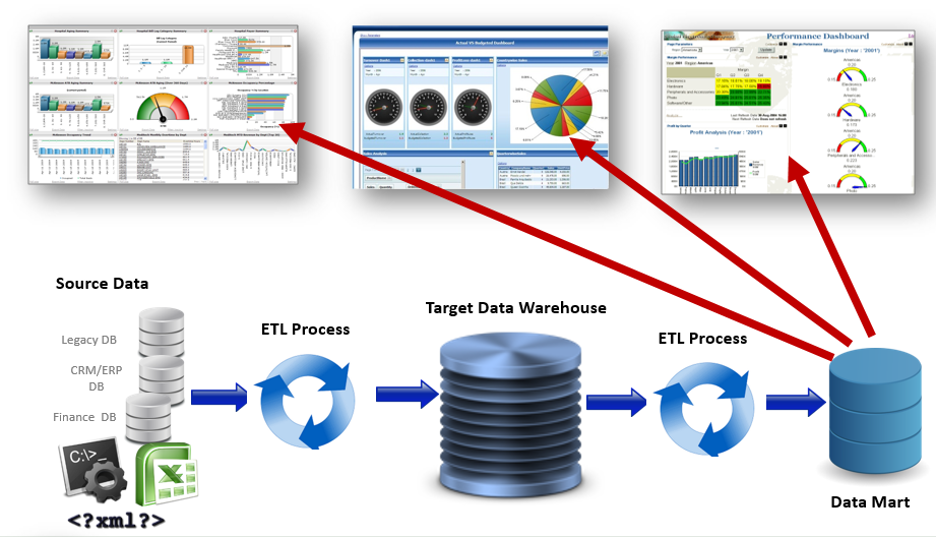
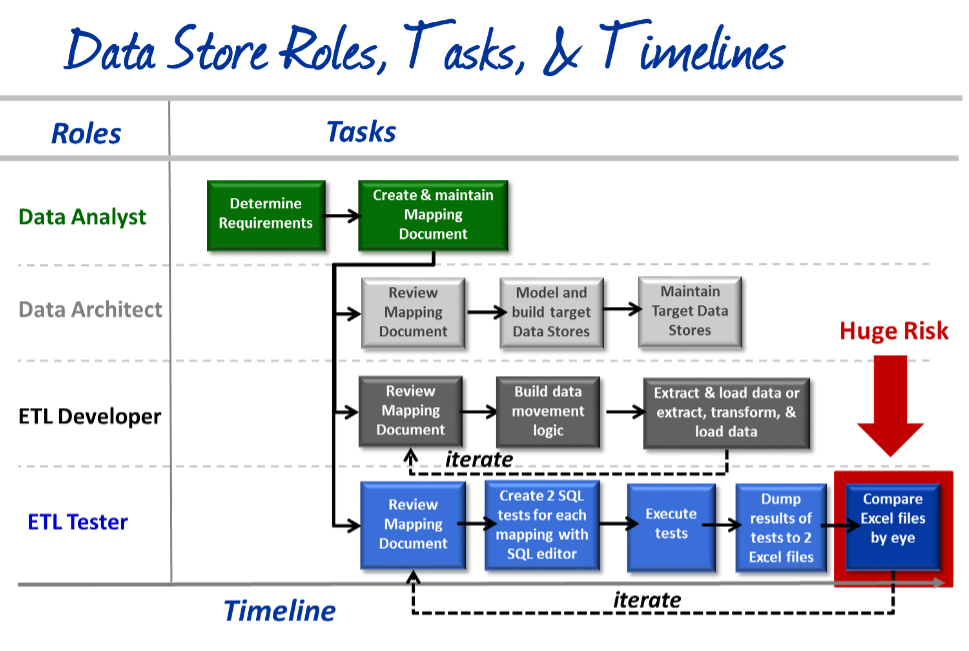
Who is involved in the ETL process?
There are at least 4 roles involved. They are:
Data Analyst: Creates data requirements (source-to-target map or mapping doc)
Data Architect: Models and builds data store (Big Data lake, Data Warehouse, Data Mart, etc.)
ETL Developer: Transforms and loads data from sources to target data stores
ETL Tester: Validates the data, based on mappings, as it moves and transforms from sources to targets
The image on the right shows the intertwined roles, tasks and timelines for performing ETL Testing with the sampling method.
Why perform ETL Testing?
-
“70% of enterprises have either deployed or are planning to deploy big data projects and programs this year”
-
“75% of businesses are wasting 14% of revenue due to poor data quality”
-
“19.2% of big data app developers say quality of data is the biggest problem they consistently face.”
-
“Data quality costs (companies) an estimated $14.2 million annually”
Bad data caused by defects in the ETL process can cause data problems in reporting that can result in poor strategic decision-making. According to analyst firm Gartner, bad data costs companies, on average, $14 million annually with some companies costing as much as $100 million.
An example of what bad data can cause:
A large fast food company depends on business intelligence reports to determine how much raw chicken to order on a monthly basis, by sales region and time of year. If these reports are not correct, then the company could order an incorrect amount which could cost the company millions of dollars in either lost revenue or wasted product.
How does ETL Testing work?
ETL Testing is a way to perform validation of the data as it moves from one data store to another. The ETL Tester uses a Mapping Document (if one exists), which is also known as a source-to-target map. This is the critical element required to efficiently plan the target Data Stores. It also defines the Extract, Transform and Load (ETL) process.
The intention is to capture business rules, data flow mapping and data movement requirements. The Mapping Document specifies source input definition, target/output details and business & data transformation rules.
The typical process for ETL Testing is as follows:
1) Review the Schema and Business Rules / Mappings
Schemas are ways in which data is organized within a database or data warehouse.
Business Rules are also known as Mappings or Source-to-Target mappings and are typically found in a Mapping Document. The mapping tables in the document are the requirements or rules for extracting, transforming (if at all) and loading (ETL) data from the source database and files into the target data warehouse or big data store. Specifically, the mapping fields show:
- Table names, field names, data types and length of both source and target fields
- How source tables / files should be joined in the new target data set
- Any transformation logic that will be applied
- Any business rules that will be applied

2) Create Test Cases
Each Mapping will typically have its own test case. Test Case will typically have two sets of SQL queries (or HQL for Hadoop). One query will extract data from the sources (flat files, databases, xml, web services, etc.) and the other query will extract data from the target (Data Warehouses or Big Data stores).

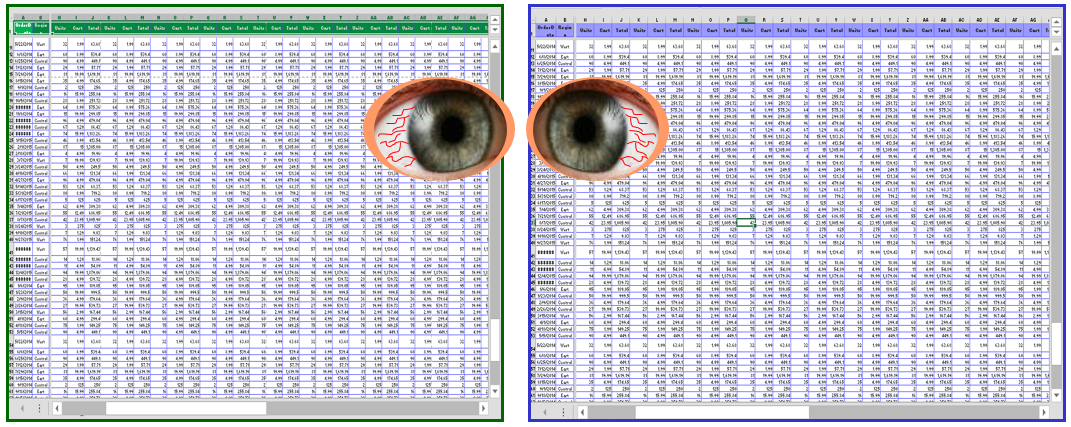
Extract data from source data stores (Left) Extract data from target Data Warehouse (Right)

3) Execute Tests, Export Results
These tests are typically executed using a SQL editor such as Toad, SQuirrel, DBeaver, or any other favorite editor. The test results from the 2 queries are saved into 2 Excel spreadsheets.

4) Compare Results
Compare all result sets in the source spreadsheet with the target spreadsheet by eye compare. (also known as“Stare & Compare”). There will be lots of scrolling to the right to compare dozens, if not hundreds of columns and lots of scrolling down to compare tens of thousands or even millions of rows.
There are 4 different methods for performing ETL testing:
- Sampling
- Minus Queries
- Using home grown tools, utilities and frameworks
- Using commercial software like QuerySurge
What is Sampling?
Sampling is the most common method and uses a SQL editor like Toad or Squirrel. The ETL Tester reviews the mapping document, writes 2 tests in the SQL editor that extract data from the (1) the source and (2) the target data stores, dumps the results into 2 Excel spreadsheets and then compares them by eye. That is why it is also called the “stare and compare” method. Many times a single test may have 100 million columns and 200 columns, meaning 20 billion data sets. Imagine having 2 monitors, each with a spreadsheet that large, and scrolling down and to the right looking for data anomalies in two 20 billion data set spreadsheets. The result is usually far less than 1% of data is compared. Learn more on ETL Testing and Sampling here >

What is a Minus Query?
A Minus Query is a query that uses the MINUS operator in SQL to subtract one result set from another result set to evaluate the result set difference. If there is no difference, there is no remaining result set. If there is a difference, the resulting rows will be displayed.
The way to test using Minus Queries is to perform source-minus-target and target-minus-source queries for all data, making sure the extraction process did not provide duplicate data in the source and all unnecessary columns are removed before loading the data for validation.

Some issues we found are:
- Minus Queries are processed on either the source or the target database, which can draw significantly on database resources (CPU, memory, and hard drive read/write)
- In the standard minus query implementation, minus queries need to be executed twice (Source-to-Target and Target-to-Source). This doubles execution time and resource utilization
- If directional minus queries are combined via a Union (a union reduces the number of queries executed by half), information about which side the extra rows are on can be lost
- Result sets may be inaccurate when duplicate rows of data exist (the minus query may only return 1 row even if there are duplicates)
Learn more about ETL Testing and Minus Queries here >
Tools, Utilities and Frameworks
Many companies have created homegrown tools, utilities or frameworks to perform ETL Testing. While this may be tailored to and work for a company’s specific needs, they are very expensive to build and maintain. As an example, the original commercial build of QuerySurge, which was released at Oracle OpenWorld in October of 2012, cost 7‑figures to build and release for version 1.0.
Also, customers who employ System Integrators (SI’s) that implement frameworks are in a conundrum. They cannot perform a comparative analysis of the SI’s framework vs. a commercial solution like QuerySurge because there is no way gain access to it – there are no detailed product specifications, no flyers, no YouTube video, no slide deck, no free trial. The customer is at high risk as they lock themselves into a utility or “framework” that only the System Integrator can support. If the customer chooses to move away from the framework, there is no ecosystem to support it and no other consultancy to help them.
Commercial Software
If a commercial solution is implemented, there is usually an abundance of information readily available about the product:
- There is typically a YouTube channel of videos
- There are lots of slide decks available
- There are reams of web pages on a web site of product information, knowledge articles, case studies, how-to videos, webinar recordings, etc.
- There is an ecosystem of partners the customer can choose from – they are typically not locked into any singular consulting firm
- There are many independent contractors that know the product
- There are training classes if the customer wants to have its employees trained
- There are free trials and free tutorials for anyone to use
- There is an import feature if the customer wishes to import tests from another system and an export feature if they decide to discontinue use of the product
Commercial software does not require an upfront cost to build and maintain, as with homegrown tools or utilities, nor does it lock customers into a closed system with no viable exit ability as with 3rd party frameworks. Commercial software provides lots of options that homegrown tools, utilities and frameworks do not offer.
How Commercial ETL Testing Tools Work
Commercial ETL Testing software, like QuerySurge, typically support a variety of use cases, such as:



Commercial software has an installer with the flexibility of installing the ETL Testing solution anywhere.
Also, commercial ETL Testing solutions can typically connect to hundreds of different data stores, ranging from traditional databases, flat files, Excel, and json to data warehouses, Hadoop, NoSQL data stores and business intelligence reports.

Support for Multiple Data Stores
Commercial ETL testing solutions support many data stores. Below is an example of 200+ data stores that QuerySurge supports:

Commercial ETL Testing solutions pull data from data sources and from data targets and quickly compare them.

The ETL testing process mimics the ETL development process by testing data from point-to-point along the data lifecycle.

Commercial ETL Testing Solutions: Robust Functionality
Commercial ETL Testing solutions are much richer in functionality and ease-of-use features than homegrown frameworks. Many provide wizards to simplify testing, DevOps for Data capabilities to integrate into your CI/CD pipeline, and the ability to analyze your data’s quality and health through reports and dashboards.
Here is an example of some of QuerySurge’s functionality:
- Projects - Multi-project support, import/export projects, global admin user, assign users and agents, user activity log reports
- Artificial Intelligence — Leverage AI-powered technology to automatically create data validation tests, including transformational tests, based on data mappings
- Smart Query Wizards — Create tests visually, without writing SQL
- Create Custom Tests - Modularize functions with snippets, set thresholds, stage data, check data types & duplicate rows, full text search, asset tagging, more
- Scheduling — Run test immediately, at a predetermined date & time or after any event from a build/release, CI/CD, DevOps or test management solution
- Data Quality at Speed - Automate the launch, execution, comparison and send auto-emailed results
- Test across different platforms — Data Warehouse, Hadoop and NoSQL stores, traditional databases, flat files, Excel, XML, JSON, mainframe, Business Intelligence reports
- DevOps for Data - API Integration (both RESTful & CLI) with build/release, continuous integration/ETL , operations/DevOps monitoring, test management/issue tracking and more
- Data Analytics & Data Intelligence - Data Analytics dashboard, Data Intelligence reports, auto-emailed results, Ready-for-Analytics back-end data access
- Test Management Integration - Out-of-the-box integration with Azure DevOps, IBM RQM, Micro Focus (formerly HP) ALM, Atlassian Jira and any other solution with API access
- BI Testing - Testing data embedded in Microsoft Power BI, Tableau, SAP BusinessObjects, MicroStrategy, IBM Cognos or Oracle OBIEE
- Available On-Premises and In-the-Cloud - Install on a bare metal server, virtual machine, any private cloud or in the Microsoft Azure Cloud as a pay-as-you-go service
- Security — AES 256 bit encryption, support for LDAP/LDAPS, TLS, Kerberos, HTTPS/SSL, auto-timeout, security hardening and more
The Bottom Line
The bottom line is that commercial ETL Testing solutions provide benefits that far outweigh their cost and provide a significant return-on-investment (see calculation here).
Some of the benefits include:
- Data quality at speed. Validate up to 100% of all data up to 1,000 x faster than traditional testing.
- Test automation. Now you can automate your data testing from the kickoff of tests to performing the validation to automated emailing of the results and updating your test management system.
- Test across platforms, whether a Big Data lake, Data Warehouse, traditional database, NoSQL document store, BI reports, flat files, JSON files, SOAP or restful web services, xml, mainframe files, or any other data store.
- DevOps for Data for Continuous Testing. Integration with most Data Integration/ETL solutions, Build/Configuration solutions, and QA/ Test Management solutions. Some vendors (i.e. QuerySurge) provide full RESTful and CLI APIs that give you the ability to create and modify source and target test queries, connections to data stores, tests associated with an execution suite, new staging tables from various data connections and customize flow controls based on run results.
- Analyze your data, with data analytics dashboards and data intelligence reports
- Integration with leading Test Management Solutions. Integrate with solutions such as Micro Focus (formerly HP) ALM/Quality Center, IBM RQM, Microsoft DevOps (formerly TFS & VSTS) and Atlassian Jira.
A commercial ETL Testing solution will help you:
- Continuously detect data issues in your CI/CD delivery pipeline
- Dramatically increase your data validation coverage
- Leverage analytics to optimize your critical data
- Improve your data quality at speed
- Provide a huge ROI
There are many commercial ETL Testing solutions currently available. Our recommendation is to run a proof-of-concept in your own environment and see which works best for you. These solutions will improve your ETL testing process, increase your data validation coverage, reduce your bad data and improve your overall data quality.
Let us know if we can assist you in any way. Happy hunting!
Get Certified as an ETL Tester now!
Learn, Earn and Inform.
- Learn everything about Data Validation & ETL Testing from our self-paced training portal
- Earn your digital badge from a renowned digital credential network and
- Inform your social media community of your new certification
Our latest certification is Certified ETL Tester. Certified ETL Testers have demonstrated an ability to strategize, plan and design a successful data validation & ETL testing project.
And it’s free for customers and partners!
Schedule a Private Demo of automated ETL Testing Leader QuerySurge
Schedule a private virtual meeting with our experts and your team. Receive a live, guided, interactive tour of QuerySurge’s features and workflows. Get answers to any questions specific to QuerySurge and your company, your industry or your architecture.




