Whitepaper
The Strategic Integration of Deterministic
Data Validation within the Modern
Data Observability Ecosystem

The escalating complexity of global data architectures, characterized by a transition from monolithic on-premises warehouses to heterogeneous multi-cloud environments, has fundamentally altered the requirements for data reliability.
Historically, organizations relied on manual spot-checks or brittle, homegrown scripts to verify data quality, a paradigm that is no longer sustainable in the era of high-velocity data pipelines and real-time analytics.
As enterprises increasingly adopt DataOps and automated delivery frameworks, the concept of "data downtime"—periods where data is missing, erroneous, or otherwise unfit for purpose—has emerged as a primary business risk.1
Within this landscape, QuerySurge occupies a unique and specialized position. While the burgeoning field of data observability focuses on the operational health of pipelines through monitoring freshness, volume, and schema changes, QuerySurge provides the deterministic validation layer necessary to prove that the data content is actually correct and compliant with complex business logic.3
The Evolution of the Data Trust Stack
The modern data lifecycle is a multi-stage journey involving ingestion from disparate sources, staging in data lakes, transformation within warehouses, and final consumption in business intelligence reports.
Each hop in this journey introduces potential points of failure that can compromise data integrity. This has led to the emergence of a "Data Trust Stack," an integrated ecosystem where specialized tools handle different dimensions of reliability.5
In this stack, data governance platforms define ownership and policies, transformation tools build modular pipelines, and observability platforms monitor for anomalies.
QuerySurge serves as the final arbiter of truth, adding automated, test-driven validation that confirms data meets defined expectations at every layer.5
Component |
Primary Function |
Core Tooling |
Role in the Trust Stack |
|---|---|---|---|
Data Governance |
Policy definition, ownership, and stewardship |
Collibra |
Defines the rules and glossaries that validation tests must enforce.5 |
Data Transformation |
Version-controlled SQL modeling and lineage |
dbt |
Builds the models that QuerySurge validates against source systems.5 |
Data Observability |
Continuous health monitoring and anomaly detection |
Monte Carlo |
Identifies pipeline breaks; QuerySurge then pinpoints the specific record-level causes.3 |
Test Data Creation |
Synthetic data generation for pipeline testing |
GenRocket |
Provides compliant test data that QuerySurge verifies through the pipeline.5 |
Data Validation |
Automated, deterministic source-to-target testing |
QuerySurge |
Proves the ultimate correctness of the data content across all layers.4 |
The synergy between these components ensures that data is not merely moving through the system, but is also accurate and analytics-ready. While an observability tool might indicate that a table has been updated, QuerySurge validates that the calculations within that table align with the source-to-target mapping documents.3
Mapping QuerySurge to the Five Pillars of Data Observability
Data observability is typically categorized into five critical pillars: Freshness, Volume, Distribution, Schema, and Lineage.1 To understand how QuerySurge fits into this space, it is necessary to examine how its deterministic validation capabilities augment or transform these traditionally passive monitoring dimensions into active quality gates.
(To expand the sections below, click on the +)
- 1) Freshness and Pipeline Latency
- 2) Volume and Completeness Metrics
- 3) Schema Drift and Structural Integrity
- 4) Distribution and Anomaly Detection
- 5) Lineage-Aware Result Tracking
Freshness and Pipeline Latency
In the observability paradigm, freshness refers to whether data is up-to-date and whether pipelines are running at the expected cadence.1 Stale data often leads to wasted resources and flawed strategic decisions. Observability tools use metadata to detect when a table has not been updated within its service-level agreement (SLA). QuerySurge enhances this by verifying the "semantic freshness" of the records. Beyond checking table update timestamps, QuerySurge can execute specific tests to ensure that the data processed in a particular batch actually falls within the intended temporal window, preventing the re-processing of old data or the premature ingestion of incomplete datasets.11
Volume and Completeness Metrics
Volume monitoring tracks the amount of data flowing through a system to identify sudden spikes or drops that might signal ingestion failures or unintended duplication.9
While observability tools provide alerts for statistical deviations in row counts, QuerySurge performs high-volume reconciliation that compares billions of records between source and target systems.14
This is particularly critical in big data environments where traditional "minus queries" fail due to performance constraints.
QuerySurge’s distributed agent architecture allows it to identify precisely which rows are missing or duplicated, rather than merely reporting a deviation in the total count.7
Schema Drift and Structural Integrity
Schema monitoring detects structural changes, such as the addition of new columns, the removal of fields, or changes in data types that can break downstream transformations.9
QuerySurge utilizes automated schema validation to ensure that target data stores remain compliant with technical specifications. By integrating schema checks into the CI/CD pipeline, QuerySurge can catch schema drift before it corrupts production analytics.17
This proactive approach transforms schema monitoring from a notification-based activity into an automated enforcement mechanism.
Distribution and Anomaly Detection
Distribution monitoring identifies shifts in the statistical properties of data, such as changes in mean values, standard deviations, or null rates.2
This is often achieved through probabilistic models and Monte Carlo simulations, which are powerful for identifying "unknown unknowns".10
QuerySurge complements this with deterministic checks and thresholding.
For instance, while an observability tool might flag a general shift in "Transaction Amounts," QuerySurge would apply specific range checks to ensure that no individual transaction violates business rules, such as a negative insurance premium or an age value outside the range of 0 to 120.12
Lineage-Aware Result Tracking
Lineage provides a map of the data's journey through the ecosystem, helping teams understand upstream dependencies and downstream impacts.2
While many observability tools provide "metadata lineage," QuerySurge offers "lineage-aware result tracking".7
This provides transparency into the accuracy of data at each hop of the pipeline. If a data job fails or a table contains erroneous data, the system can show not only the affected tables but also the specific transformation logic that introduced the error.3
This integration of result history with lineage-aware tracking is essential for organizations requiring audit-ready documentation for compliance initiatives.7
Technical Mechanisms of Automated Validation
The ability of QuerySurge to scale validation across complex enterprise architectures is rooted in several key technical components, including its distributed agent architecture, extensive API coverage, and its AI-powered test generation engine.
(To expand the sections below, click on the +)
Distributed Agent Architecture
QuerySurge utilizes a hub-and-spoke model to manage high-volume testing across heterogeneous environments. The central application server coordinates multiple QuerySurge Agents, which are the architectural components that execute queries against source and target data stores.12 These agents can be deployed on various virtual machines or desktops, but notably, they are recommended to be isolated from the database servers themselves to avoid resource contention.12
Feature |
Technical Implementation |
Value to Observability |
|---|---|---|
Parallel Execution |
Agents run tests in parallel across billions of records.7 |
Ensures high-speed validation for big data and real-time pipelines. |
Vendor Agnostic |
Supports any data store with a JDBC-compliant driver.5 |
Provides a single unified view across 200+ disparate technologies.5 |
Distributed Scaling |
Horizontal scaling via additional agents for large environments.7 |
Handles thousands of test cases without performance degradation. |
Heterogeneous Comparison |
Reconciles data between different platforms (e.g., JSON to SQL Server).5 |
Ensures integrity even as data formats change across the pipeline. |
By offloading the comparison logic to these distributed agents, QuerySurge can perform row-by-row and cell-level comparisons that would otherwise be computationally prohibitive on the production databases.4
The Role of AI in Scaling Validation Coverage
As the number of data mappings grows into the thousands, the manual creation of testing scripts becomes a significant bottleneck. QuerySurge addresses this through two generative AI solutions: Mapping Intelligence and Query Intelligence.4
Mapping Intelligence is an automated engine that interprets data mapping documents—the blueprints for ETL processes—and automatically generates complete validation test suites.24 This includes complex transformation logic that would typically require hours of manual SQL development per mapping.24 By reducing test development time from hours to minutes, Mapping Intelligence enables organizations to achieve 100% data coverage, eliminating the critical blind spots associated with traditional sampling methods.24
Query Intelligence provides a conversational chat interface that helps users generate and refine individual tests through natural language.4 This allows non-SQL users to contribute to the data testing lifecycle while accelerating the productivity of experienced engineers who can describe their testing intent in plain English and receive native SQL in return.11
Shifting Left: Integrating Validation into the DataOps Pipeline
The "Shift-Left" philosophy, which involves moving testing and quality control earlier in the development lifecycle, is a foundational principle for modern data engineering.26 QuerySurge facilitates this by embedding data validation directly into CI/CD pipelines, acting as a quality gatekeeper that ensures only validated data reaches production environments.4
(To expand the sections below, click on the +)
Universal DevOps Integration
QuerySurge integrates with virtually any DevOps or CI/CD solution in the market, including Jenkins, Azure DevOps, GitHub Actions, and Bamboo.7 This is achieved through a robust RESTful API that offers over 100 API calls and hundreds of customizable parameters.28
Integration Category |
Technical Detail |
Strategic Benefit |
|---|---|---|
Orchestration |
API-driven execution following ETL/ELT job completion.7 |
Automates validation in the DataOps workflow, reducing manual intervention. |
API Documentation |
Swagger-powered interactive documentation for developers.4 |
Speeds up integration by allowing teams to test endpoints in real-time. |
Alerting & Notifications |
Webhooks for real-time alerts to Slack, Teams, or Jira.12 |
Ensures immediate feedback to engineering teams when data tests fail. |
Dynamic Management |
Programmatically create and update tests and data stores on demand.28 |
Allows the validation layer to adapt automatically as new environments are deployed. |
This level of automation ensures that data testing is a continuous, integrated component of the pipeline, rather than a bottlenecked, post-development activity.24 For example, a Jenkins pipeline can be configured to run dbt models, then automatically trigger a suite of QuerySurge tests. If the tests pass, the pipeline proceeds to production; if they fail, the system can halt the deployment or trigger a rollback.6
Closing the Gap: Validation at the Business Intelligence Layer
A critical blind spot in many observability strategies is the "last mile" of the data journey—the visualization layer. Data that is technically "healthy" in the warehouse can still be misinterpreted or incorrectly displayed in BI reports due to faulty report-level calculations, filter issues, or vendor-specific upgrade bugs.7
QuerySurge’s BI Tester module addresses this by verifying that the data visualized in dashboards matches the source data exactly.4 It provides cell-level accuracy checks across major platforms such as Power BI, Tableau, Strategy, and SAP Business Objects.7 By validating data from the visual layer down to the underlying data store, QuerySurge ensures that executive decisions are based on trusted, verified analytics.7
BI Tool Supported |
Validation Depth |
Key Use Case |
|---|---|---|
Microsoft Power BI |
Cell-level, DAX query profiling.4 |
Validating semantic models and report integrity during migrations. |
Tableau |
Automated regression and upgrade testing.5 |
Ensuring consistency across multi-vendor BI environments. |
SAP Business Objects |
Mapping-to-report reconciliation.4 |
Validating complex legacy reports during cloud modernization. |
Oracle BI / OBIEE |
Source-to-visual reconciliation.5 |
Maintaining data accuracy across large enterprise BI deployments. |
This capability extends observability into the consumption layer, providing a complete end-to-end view of data reliability that monitoring tools focused solely on pipeline health cannot achieve.3
Comparative Analysis: QuerySurge vs. Passive Monitoring Tools
To effectively position QuerySurge within the observability ecosystem, it is helpful to contrast its specialized validation capabilities with those of general-purpose observability and rule-based monitoring tools.
(To expand the sections below, click on the +)
QuerySurge vs. Monte Carlo
The relationship between QuerySurge and Monte Carlo is complementary rather than competitive. Monte Carlo focuses on "Data-at-Rest" and "Data-in-Motion" from a health perspective, identifying when pipelines break or statistical properties shift.3 QuerySurge, conversely, focuses on "Data-in-Process," ensuring that transformation logic is executed correctly according to explicit business rules.3
- Monte Carlo: Answers the question, "Where should we look?" by detecting anomalies in freshness, volume, and schema.3
- QuerySurge: Answers the question, "Is it correct?" by performing row-by-row comparisons and transformation verification.3
The synergy between the two allows for a rapid operational response followed by formal audit-ready validation.3
QuerySurge vs. IceDQ and RightData
When compared to other tools in the data quality space, QuerySurge stands out due to its deep specialization in automated regression testing and enterprise-grade DevOps integration.15
Feature |
QuerySurge |
IceDQ |
RightData |
|---|---|---|---|
Primary Focus |
Dedicated automated data testing and validation.15 |
Rules-based monitoring and anomaly detection.15 |
Data integration + data testing platform.34 |
AI Capabilities |
Generative AI for bulk test creation and SQL refinement.15 |
No AI-driven test creation functionality.15 |
No comparable AI-driven test generation.34 |
DevOps API |
100+ API calls, Swagger documentation, native CI/CD gates.28 |
Supports automation but lacks equivalent API depth.15 |
Requires manual scripting for CI/CD integration.34 |
BI Validation |
Specialized BI Tester for cell-level report validation.7 |
No direct BI layer validation module.15 |
BI testing is manual and limited in scope.34 |
Deployment |
Flexible: On-prem, Cloud-hosted, and Hybrid.15 |
Primarily On-prem and some cloud options.15 |
Primarily Cloud-first with fewer hybrid options.34 |
The depth of QuerySurge’s features, particularly its AI-powered test creation and broad connectivity, makes it the preferred choice for Global 2000 enterprises with complex, high-volume data ecosystems.15
The Impact of Data Downtime and the ROI of Validation
The financial implications of poor data quality are profound. Analyst firm Gartner estimates that bad data costs organizations an average of $14 million annually, with some large enterprises losing as much as $100 million.12 These costs stem from flawed strategic decisions, operational disruptions, and regulatory non-compliance.12
By automating data validation, QuerySurge provides a significant Return on Investment (ROI), often cited as high as 1,500%.11 This ROI is realized through several key mechanisms:
- Efficiency Gains: Automated testing cycles are 89% faster than manual validation methods, allowing teams to deploy data products more quickly.5
- Defect Reduction: Continuous pipeline testing results in a near-zero defect escape rate, preventing costly errors from reaching production reports.5
- Risk Mitigation: Comprehensive coverage ensures that even subtle data bugs—such as numeric precision errors or null translations—are identified early.12
- Resource Optimization: AI-driven test creation reduces the dependency on highly skilled SQL testers, allowing data engineers to focus on building rather than firefighting.24
In an e-commerce context, for example, incorrect product pricing or inventory levels in a BI report can lead to millions of dollars in lost revenue or wasted product.12 QuerySurge validates the complex logic behind these reports to ensure that ordered amounts and pricing reflect the actual business rules applied during the ETL process.12
Statistical Outlier Detection and Deterministic Range Checks
While the core of QuerySurge is deterministic, its analytical capabilities allow it to detect anomalies that manifest as outliers. Outlier detection is a critical component of data integrity, identifying points that deviate significantly from expected patterns.21 These can include sudden spikes in financial transactions, missing values in a time-series, or duplicated customer records.21
While pure observability tools use statistical methods like 𝒵-scores to find outliers, QuerySurge allows users to define custom thresholds and business-informed range checks.12 A 𝒵-score is calculated as:
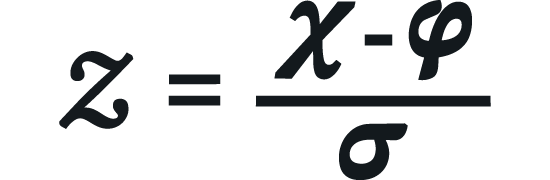
Where 𝝌 is the data point, 𝝋 is the population mean, and 𝝈 is the standard deviation.35 QuerySurge can execute queries that identify data points where |𝒵| > 𝟑, while simultaneously applying business-specific rules, such as "No transaction should exceed $10,000 for this user category," regardless of the statistical mean.12 This dual approach ensures that anomalies are caught whether they are statistically improbable or business-prohibited.
Implementation of Audit and Compliance Readiness
For organizations in regulated sectors like insurance or finance, the ability to demonstrate a controlled environment is non-negotiable.22 QuerySurge provides the necessary infrastructure to meet rigorous compliance standards such as SOX, HIPAA, and GDPR.18
(To expand the sections below, click on the +)
Detailed Audit Trails
QuerySurge maintains a complete audit trail of all test executions, user actions, and modifications to test assets.12 This includes:
- Version Control: History tracking for all "QueryPairs" and test suites, identifying who made changes and when.7
- Execution Logs: Verifiable and traceable results for every test run, providing a tamper-proof record for auditors.7
- Reporting: Presentation-ready Data Intelligence Reports that summarize testing status, project health, and data quality trends.4
Lineage-Aware Validation for Governance
The integration of lineage-aware validation is particularly powerful for governance initiatives. By tracking data flows and the associated validation results across the pipeline, organizations can prove to regulators that data remained consistent and accurate as it was moved from source systems into regulatory reports.7 This transforms lineage from a passive map into an active evidence-gathering mechanism that supports the entire "Data Trust" lifecycle.3
Conclusion: The Strategic Value of Unified Validation and Observability
The convergence of high-volume data validation and continuous observability represents the next generation of data reliability.
QuerySurge fits into the observability space not as a replacement for monitoring tools, but as the essential deterministic layer that provides depth and certainty to the broader reliability strategy.
By shifting validation left into the CI/CD pipeline, leveraging AI to scale coverage, and extending quality checks into the BI visualization layer, QuerySurge eliminates the "trust gap" that often exists between technical systems and business users.
In an environment where the cost of bad data can reach hundreds of millions of dollars, the ability to verify up to 100% of data with row-level precision is a critical requirement for any data-driven enterprise.
The strategic integration of QuerySurge within the Data Trust Stack—alongside governance, transformation, and observability platforms—creates an end-to-end ecosystem where data is not only moving and healthy but is also proven to be accurate, compliant, and ready to drive confident business decisions.
As organizations continue to modernize their data stacks, the role of automated, deterministic validation will only grow in importance, serving as the ultimate arbiter of data truth in a complex and ever-evolving digital landscape.
Works cited
- Introducing the 5 Pillars of Data Observability | by Barr Moses | TDS Archive | Medium, accessed February 18, 2026
https://medium.com/data-science/introducing-the-five-pillars-of-data-observability-e73734b263d5 - What Is Data Observability? 5 Key Pillars To Know In 2026 - Monte Carlo, accessed February 18, 2026
https://www.montecarlodata.com/blog-what-is-data-observability/ - Monte Carlo | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/integrations/monte-carlo - QuerySurge: Home, accessed February 18, 2026
https://www.querysurge.com/ - Integrations | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/integrations - dbt - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/integrations/dbt - QuerySurge: Seven Proven Value Pillars, accessed February 18, 2026
https://www.querysurge.com/product-tour/seven-proven-value-pillars - Data Observability — Dynatrace Docs, accessed February 18, 2026
https://docs.dynatrace.com/docs/observe/data-observability - Understanding data observability as proactive monitoring for data quality | Datafold, accessed February 18, 2026
https://www.datafold.com/blog/what-is-data-observability - What Is Data Observability? Key Pillars and Benefits - Databricks, accessed February 18, 2026
https://www.databricks.com/glossary/data-observability - Roles and Uses - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/product-tour/roles-uses - ETL Testing | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/etl-testing - Solving the Enterprise Data Validation Challenge - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/business-challenges/solving-enterprise-data-validation - Big Data Testing - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/testing-big-data - QuerySurge vs IceDQ - Competitive Analysis, accessed February 18, 2026
https://www.querysurge.com/product-tour/competitive-analysis/icedq - Drift Detection: Monitoring Schema, Logic, and Metric Changes in Real-Time - Medium, accessed February 18, 2026
https://medium.com/@manik.ruet08/drift-detection-monitoring-schema-logic-and-metric-changes-in-real-time-a2398428ccc1 - Data warehouse testing tools: Top 9 picks with use cases - RudderStack, accessed February 18, 2026
https://www.rudderstack.com/blog/data-warehouse-testing-tools/ - JSON | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/integrations/json - QuerySurge DevOps for Data Use Cases, accessed February 18, 2026
https://www.querysurge.com/solutions/querysurge-for-devops/use-cases - Monte Carlo Magic: Three Sampling Methods That Power Modern ML - Medium, accessed February 18, 2026
https://medium.com/@mandeep0405/monte-carlo-magic-three-sampling-methods-that-power-modern-ml-98b3a2b34eb4 - Spotting Data Anomalies in Your Data Platform with Monte Carlo Simulations - digna.ai, accessed February 18, 2026
https://www.digna.ai/spotting-data-anomalies-in-your-data-platform-with-monte-carlo-simulations - Ensuring Data Integrity in the Insurance Industry - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/resource-center/white-papers/ensuring-data-integrity-a-deep-dive-into-data-validation-and-etl-testing-in-the-insurance-industry - Competitive Analysis: QuerySurge vs DataGaps, accessed February 18, 2026
https://www.querysurge.com/product-tour/competitive-analysis/datagaps - Addressing Enterprise Data Validation Challenges | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/resource-center/white-papers/ensuring-data-integrity-driving-confident-decisions-addressing-enterprise-data-validation-challenges - The Generative Artificial Intelligence (AI) solution… - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/solutions/querysurge-artificial-intelligence - What Is Shift Left in Data Integration? Key Concepts & Benefits - Confluent, accessed February 18, 2026
https://www.confluent.io/learn/what-is-shift-left/ - What "Shifting Left" Means and Why it Matters for Data Stacks, accessed February 18, 2026
https://www.rilldata.com/blog/what-shifting-left-means-and-why-it-matters-for-data-stacks - Moving Testing into your CI/CD Pipeline | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/business-challenges/devops-for-data-challenge - QuerySurge Review: Features, Pricing & Alternatives 2025 | TestGuild, accessed February 18, 2026
https://testguild.com/tools/querysurge - QuerySurge & Webhooks | QuerySurge, accessed February 18, 2026
https://www.querysurge.com/services/webhooks - How to Build a DevOps for Data Testing Pipeline from Jenkins to JIRA - QuerySurge, accessed February 18, 2026
https://www.querysurge.com/resource-center/mediaitem/how-to-build-a-devops-for-data-testing-pipeline-from-jenkins-to-jira - The 10 Best Data Observability Tools in 2025 - SYNQ, accessed February 18, 2026
https://www.synq.io/blog/the-10-best-data-observability-tools-in-2025 - Competitive Analysis: QuerySurge vs Tricentis Data Integrity, accessed February 18, 2026
https://www.querysurge.com/product-tour/competitive-analysis/tricentis - QuerySurge vs RightData - Competitive Analysis, accessed February 18, 2026
https://www.querysurge.com/product-tour/competitive-analysis/rightdata - 100+ Big Data Interview Questions and Answers 2025 - ProjectPro, accessed February 18, 2026
https://www.projectpro.io/article/big-data-interview-questions-/773



