Observability Alone Is
Not Validating Data
Continuous data validation that proves
your data is correct, not just delivered.

The Challenge
Data breaks quietly, then shows up loudly.
Row counts and job status can look fine while data is incomplete, incorrect, late, or drifting. Teams lose hours in war rooms trying to figure out what changed and who owns the fix.
Common pain points:
- Silent data drift after logic or schema changes
- Partial loads, missed refreshes, and broken dependencies
- Source to target mismatches after ETL/ELT
- Broken metrics and dashboards discovered by stakeholders
- Slow root cause analysis across multiple tools and teams
Data Observability You Can Trust
QuerySurge adds the missing layer to observability: automated data validation across sources, pipelines, warehouses, and BI, so you catch issues early and resolve them fast.
The QuerySurge solution
QuerySurge enables data observability by continuously validating data correctness at scale.
Instead of guessing whether data is trustworthy, QuerySurge proves it with automated, repeatable tests that run where your data lives and wherever it moves.
What you get:
- Early detection before bad data reaches analytics and operations
- Source to target validation that confirms transformations and business rules
- Fast diagnosis with variance detail, trends, and historical context
- Operational controls that fit directly into DataOps and governance programs
How it works
1) Connect to your environment
QuerySurge connects to your sources, lakes, data warehouses, data marts, and BI layers through flexible data stores and agents.
2) Build validations that matter
Create automated tests for:
- Reconciliation (source vs target, stage vs warehouse, mart vs BI)
- Transformation logic (joins, filters, aggregations, derived fields)
- Business rules (thresholds, referential integrity, completeness)
3) Automate runs in your workflow
Run test suites:
- On schedules (hourly, daily, per load)
- Triggered by pipelines and orchestration tools
- From CI/CD using the QuerySurge REST API and webhooks
4) Act on results immediately
Get pass/fail visibility, detailed variance, and alerts routed to the right team, with the context needed to fix issues fast.
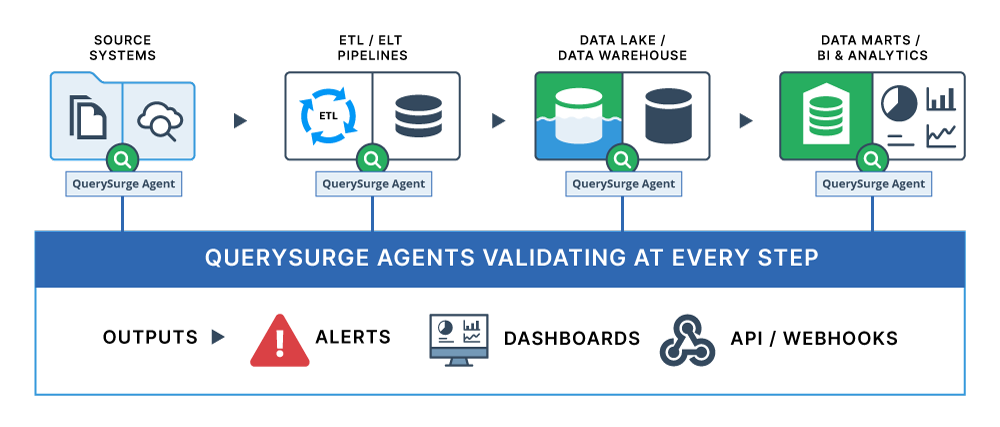
Key Capabilities
Function |
Details |
|---|---|
Continuous Validation across the lifecycle |
Validate data at every checkpoint:
|
Automation and Integration |
|
Enterprise Scale and Governance |
|
Results Analytics and Trending |
|
Where QuerySurge fits in a data observability stack
Monitoring shows you which jobs ran. QuerySurge tells you whether the data is right. Pipeline and infrastructure monitoring are necessary, but they do not confirm correctness. QuerySurge complements observability platforms by providing the data validation layer that proves trust.
Common use cases
- Production data quality controls for critical datasets
- Cloud migrations and modernization (prove parity and catch drift)
- Data warehouse and lakehouse reconciliation
- Release confidence for dbt, SQL, ETL/ELT changes
- BI trust: detect broken metrics before stakeholders do
Outcomes
- Faster detection of data defects before they impact the business
- Reduced incident volume and shorter root cause cycles
- Higher confidence in dashboards, analytics, and operational reporting
- Stronger governance with automated, repeatable controls
- Scalable validation that replaces manual SQL spot checks
Make data trust measurable.
Bring continuous data validation to your observability strategy with QuerySurge.

FAQ: How to Add the Missing Layer to Observability
- What is the missing layer in data observability?
- Why is observability alone not enough?
- What is the difference between data observability and data validation?
- How does QuerySurge complement data observability platforms?
- Why do enterprises need validation in addition to observability?
- How do teams prove whether an observability alert reflects a real data defect?
- Can observability detect whether source-to-target data is correct?
- How does QuerySurge help validate data pipelines after observability detects an issue?
- How do organizations validate data quality beyond anomaly detection?
- How does validation improve trust in observability programs?
- Can QuerySurge work with observability initiatives in cloud and hybrid environments?
- How does QuerySurge support root-cause analysis for data issues?
- How does the missing layer to observability support governance and compliance?
- How does QuerySurge help teams catch issues before they affect dashboards and reports?
- What role does automation play in adding the missing layer to observability?
- How does QuerySurge add the missing layer to observability?
- What ROI can organizations expect by combining observability with validation?
What is the missing layer in data observability?
The missing layer is validation. Observability can tell you that something has changed, drifted, or looked suspicious.
Why is observability alone not enough?
Observability is useful for detecting signals, but it does not always prove data integrity. Automated data validation adds that proof by validating source-to-target data, transformation results, and business-rule accuracy.
What is the difference between data observability and data validation?
Data observability monitors for anomalies, freshness issues, volume changes, and schema drift. Data validation complements that by testing whether data values, mappings, and transformations are truly correct.
How does QuerySurge complement data observability platforms?
QuerySurge works alongside observability by adding automated validation where observability leaves off. Together, they help organizations detect issues and verify the actual integrity of the data.
Why do enterprises need validation in addition to observability?
Enterprises need more than alerts. They need evidence that the data is accurate enough for analytics, reporting, compliance, and operations.
How do teams prove whether an observability alert reflects a real data defect?
They need to validate the underlying data across systems and rules. Automated data validation helps teams investigate alerts by testing whether the data actually failed completeness, accuracy, or transformation expectations.
Can observability detect whether source-to-target data is correct?
Not completely. Observability may show that something has changed, but not whether the data landed correctly, transformed properly, and matches what the business expects.
How does QuerySurge help validate data pipelines after observability detects an issue?
Once an issue is flagged, QuerySurge can validate the affected data across pipeline stages, systems, and outputs. This helps teams move from suspicion to confirmation faster.
How do organizations validate data quality beyond anomaly detection?
They need automated testing that compares records, checks business rules, and verifies transformations.
How does validation improve trust in observability programs?
Observability becomes more actionable when teams can verify what alerts actually mean. Data validation helps turn alerts into validated findings, which improves confidence in triage and resolution.
Can QuerySurge work with observability initiatives in cloud and hybrid environments?
Yes. QuerySurge supports validation across cloud, on-premises, and hybrid ecosystems, helping organizations add a stronger integrity layer to modern observability strategies.
How does QuerySurge support root-cause analysis for data issues?
By validating data across source systems, transformations, and targets, QuerySurge helps isolate where integrity broke down. That makes it easier to trace issues back to the pipeline stage or rule that failed.
How does the missing layer to observability support governance and compliance?
Governance and compliance require proof, not just alerts. Data validation provides measurable results that support data control verification and audit readiness.
How does QuerySurge help teams catch issues before they affect dashboards and reports?
QuerySurge validates data earlier in the delivery process, enabling defects to be identified before they reach business users. That gives organizations a more proactive control point than monitoring alone.
What role does automation play in adding the missing layer to observability?
Automation makes validation practical at enterprise scale. It reduces manual checking by running repeatable tests across complex data environments and recurring workflows.
How does QuerySurge add the missing layer to observability?
QuerySurge adds the validation layer that observability alone does not provide. It helps organizations verify that data is accurate, complete, and trustworthy across pipelines, platforms, and downstream outputs.
What ROI can organizations expect by combining observability with validation?
Organizations can reduce false alarms, speed up root-cause analysis, improve trust in analytics, and catch defects earlier. Data validation helps turn observability into a more complete data integrity strategy.



