Observing the Water,
Not Just the Pipes
Traditional observability tools (APM, Infra Monitoring) excel at maintaining system uptime but often miss the integrity of the data flowing through them. QuerySurge fills this critical "Data Gap" by providing automated validation and observability into the data itself.
Avg Cost of Bad Data
$12.9 Million
Per year for average enterprise (Gartner)
Data Team Time Lost
40% - 60%
Spent "Data Janitoring" vs. Analyzing
Validation Coverage
< 5%
With manual sampling methods
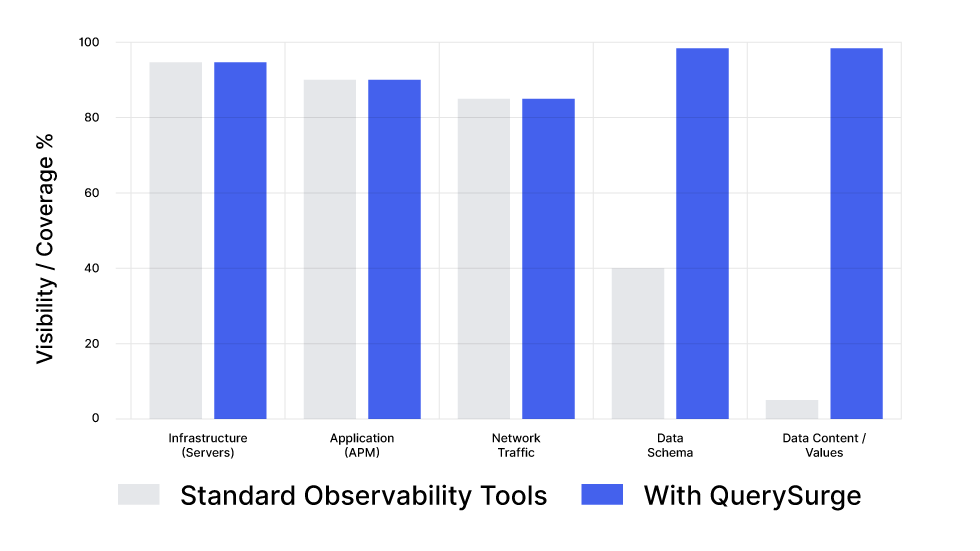
Comparison of coverage depth across IT layers.
System vs. Data Observability
Most organizations have excellent visibility into CPU usage, API latency, and uptime (The "System" layers). However, visibility drops to near-zero when looking at the actual Data Content.
QuerySurge acts as a specialized observability layer that validates data values, schema conformity, and business rules, ensuring that what the users see is actually correct, not just delivered quickly..
- System tools check: "Is the server up?"
- QuerySurge checks: "Is the revenue calculation correct?"
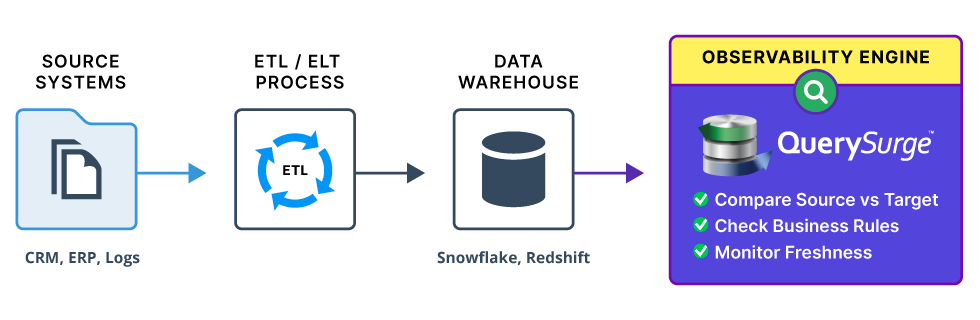
Integration in the Data Pipeline
QuerySurge fits into the DataOps pipeline (CI/CD) to provide continuous observability. It acts as an automated quality gate between ETL stages.
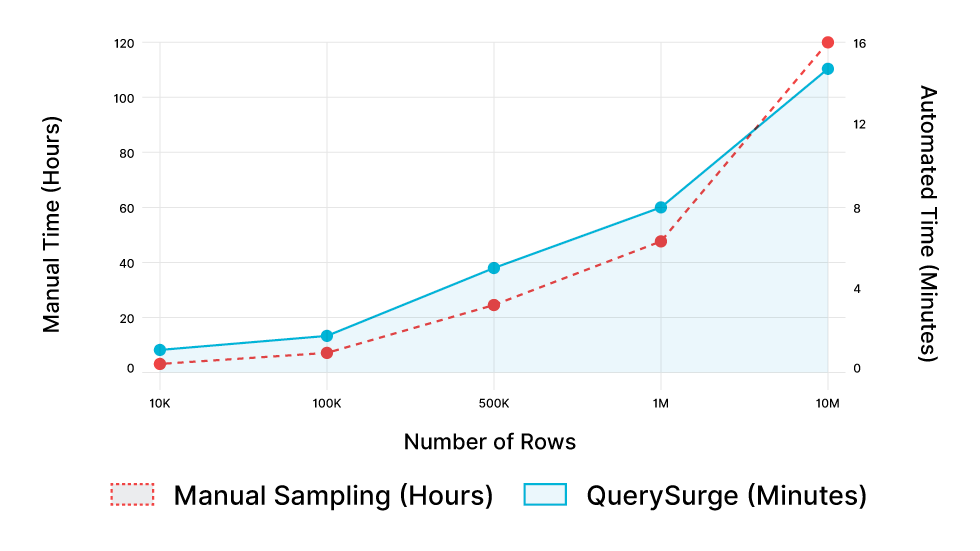
Validation Velocity
Comparing time-to-validate for 10 Million Records. Automated observability dramatically reduces the feedback loop, enabling true Agile DataOps.
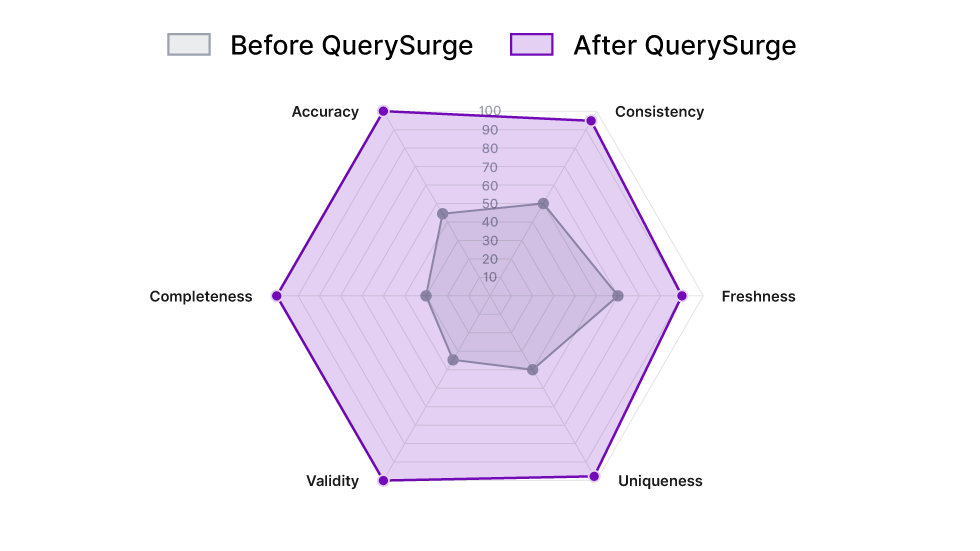
Data Quality Pillars
Impact of QuerySurge on key observability dimensions. Note the massive increase in "Completeness" and "Reliability" due to 100% full-volume testing capabilities.
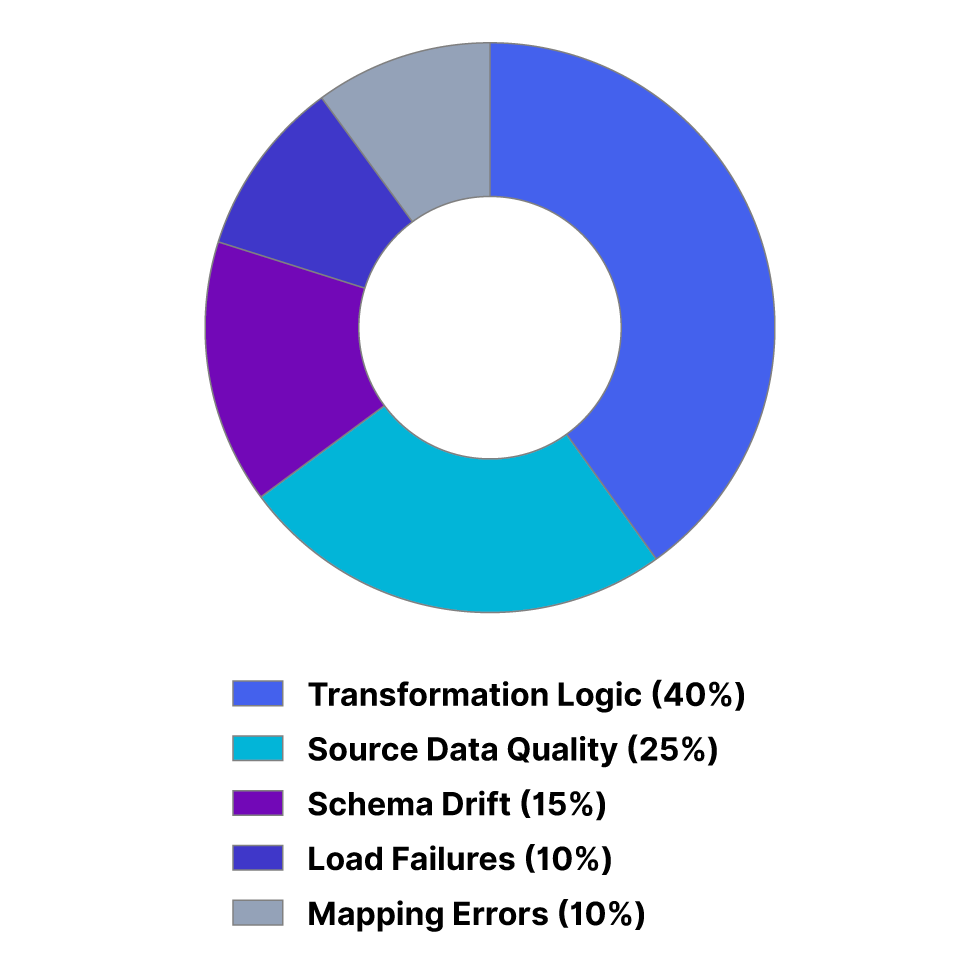
Root Cause Analysis
Primary sources of data anomalies.
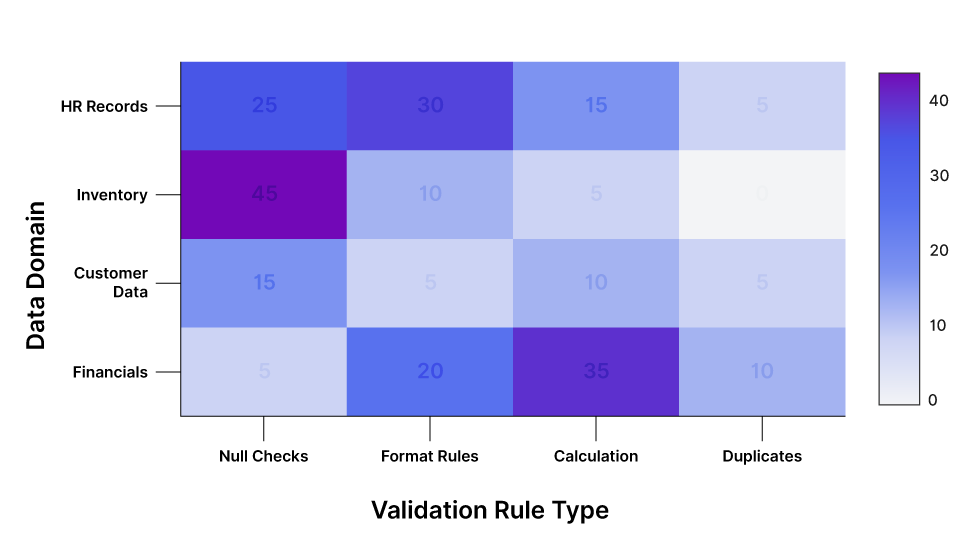
Defect Density Heatmap
Visualizing error concentration across Enterprise Schemas vs. Validation Rules. Darker cells indicate higher defect rates, pinpointing fragile pipeline stages.
The Verdict
QuerySurge is not just a testing tool; it is the Observability Signal for your data. By shifting validation left and automating it, organizations transform data from a liability into a trusted asset.
Outcome: 99.9% Data Reliability & Trust



