What is QuerySurge?
It’s the smart data testing solution that leverages
artificial intelligence to automate the data validation
& ETL testing of your critical data

About QuerySurge
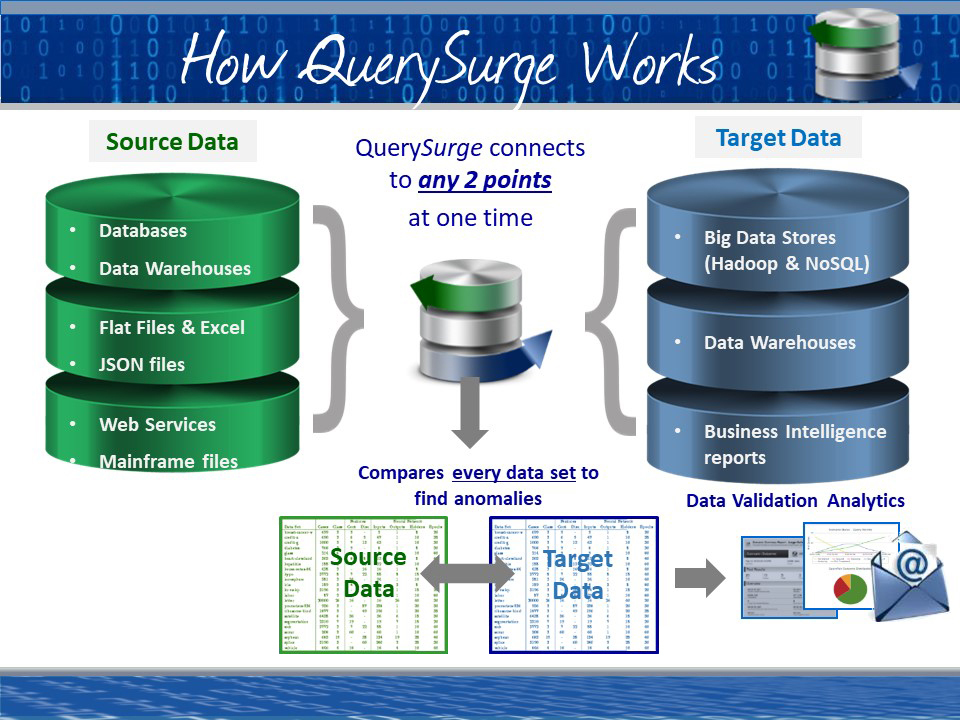
QuerySurge is an enterprise-grade data quality platform that automates the validation of data across your entire ecosystem — from data warehouses and big data lakes to BI reports and enterprise applications.
With AI-powered insights, scalable architecture, and seamless CI/CD integration, QuerySurge ensures data integrity at every stage of the pipeline — accelerating delivery, reducing risk, and driving confident decision-making.
Automated Data Testing Use Cases
QuerySurge provides the smart data testing solution for your automated testing needs.
Data Warehouse & ETL Testing
Automate the data validation & testing of Data Warehouses and the ETL process. more ⇒

Big Data Testing
Test any Big Data implementation, whether it be Hadoop or NoSQL data store from all major vendors. more ⇒

DevOps for Data /
Continuous TestingDynamically create data validation tests and integrate with other solutions in your DataOps pipeline. more ⇒

Data Migration Testing
Migrating from legacy systems to a new system, from one vendor to another, or from on-prem to the cloud. more ⇒

BI Report Testing
Retrieve data from reports and validate that data against a source or target data or another report. more ⇒

Enterprise App / ERP Testing
Automate the testing of data feeds into/out of ERP, CRM, HR system, or any large enterprise system. more ⇒
Challenges We Solve
- Your need for enterprise data validation. QuerySurge will empower your teams to trust their data, accelerate delivery, and reduce the cost and risk of bad data across your entire enterprise.
- Your need to comply with regulatory compliance. QuerySurge delivers full audit trails, end-to-end data lineage tracking, and exportable, presentation-ready reports — giving you the visibility and proof needed for audits and compliance.
- Your need to automate your manual testing process. Now you can leverage artificial intelligence through QuerySurge AI to quickly automate transformational tests and utilize the Query Wizards for quick table-to-table, column-to-column, row-to-row, and row count compares — all without writing any SQL. more »
- Your need for data quality at speed. Validate up to 100% of all data up to 1,000x faster than traditional testing. more »
- Your need to test across platforms. Whether a Big Data lake, Data Warehouse, traditional database, NoSQL document store, BI reports, flat files, JSON files, SOAP or restful web services, XML, mainframe files, or any other data store, QuerySurge can connect to 200+ data stores. more »
- Your need to integrate data validation into your CI/CD pipeline. QuerySurge offers the industry’s most advanced DevOps for Data solution, featuring 60+ API calls and full Swagger documentation. It seamlessly integrates with leading Data Integration/ETL platforms, Build/Configuration tools, and QA/Test Management systems. more»
- Your need to analyze your data quickly. QuerySurge’s Data Analytics Dashboard & Data Intelligence Reports will help you track, analyze, and communicate the quality and progress of your data testing projects with clarity and confidence. more »
- Your need to get up and running quickly. QuerySurge is simple to learn and use, with a built-in tutorial that gets you up and running in under 60 minutes. We also offer complimentary self-paced training courses and digital certifications to ensure you gain all the knowledge you need.


- To see the full list of technologies supported, visit this page»
Key Features
- Projects — Multi-project support in a single instance, new Global Admin user, assign users and agents, import and export projects, user activity log reports
- Artificial Intelligence – Leverage AI-powered technology to automatically create data validation tests, including transformational tests, based on data mappings
- Smart Query Wizards — Create tests visually, without writing SQL, perform column/table/row level comparisons, auto-matching of columns
- Create Custom Tests — Modularize functions with snippets, set thresholds, stage data, check data types & duplicate rows, full text search, asset tagging
- Scheduling — Run test immediately, at a predetermined date & time or after any event from a build/release, CI/CD, DevOps or test management solution
- DevOps for Data — API Integration (both RESTful & CLI) with build/release, continuous integration/ETL , operations/DevOps monitoring, test management/issue tracking and more. Swagger documentation.

- Run Dashboard — View test execution progress live via graphical displays, drill-down into data to examine results, see real-time statistics for executed tests, alert your team about the status of execution via custom email notifications
- Data Analytics & Data Intelligence — Data Analytics dashboard, Data Intelligence reports, auto-emailed results, Ready-for-Analytics back-end data access
- Test Management Integration — Out-of-the-box integration with Azure DevOps, IBM RQM, Micro Focus (formerly HP) ALM, Atlassian Jira and any other solution with API access

- BI Testing — Testing data embedded in Microsoft Power BI, Tableau, SAP BusinessObjects, MicroStrategy, IBM Cognos or Oracle OBIEE
- Available On-Premises and In-the-Cloud — Install on a bare metal server, virtual machine, any private cloud or in the Microsoft Azure Cloud as a pay-as-you-go service
- Security — AES 256-bit encryption, support for LDAP/LDAPS, TLS, Kerberos support, HTTPS/SSL, auto-timeout, security hardening and more
For more on QuerySurge features, visit here ⇒

QuerySurge will help you:
- Leverage artificial intelligence to quickly & easily increase test coverage
- Continuously detect data issues in the delivery pipeline
- Utilize analytics to optimize your critical data
- Improve your data quality at speed
- Provide a huge ROI
But don’t believe us (or our clients). Try it for yourself.
Check out our free trials and great tutorial




