Whitepaper
A Comprehensive Analysis of
Automated Validation of Snowflake
with QuerySurge
The transformation of global enterprise data ecosystems has reached a critical juncture where the adoption of cloud-native architectures is no longer a strategic option but a fundamental requirement for operational viability.
Central to this evolution is the Snowflake Data Cloud, a platform that has redefined the parameters ofscalability, performance, and data accessibility through its unique separation of storage and compute layers.1
As organizations migrate massive datasets from legacy on-premises environments such as Teradata and Oracle to Snowflake, the risk profile associated with data integrity has shifted significantly.2
The traditional methods of manual data validation, often characterized by sampling and “stare-and-compare” techniques, have proven inherently incapable of addressing the volume and velocity of modern data pipelines.4 In this context, the deployment of an automated, AI-driven validation framework becomes the primary mechanism for ensuring that the data powering business intelligence and artificial intelligence initiatives remains accurate, complete, and trustworthy.4
Technical Foundation of the Snowflake Data Cloud
The effectiveness of any validation strategy is predicated on a profound understanding of the target architecture. Snowflake’s data platform is delivered as a self-managed service, which eliminates the administrative burden of hardware configuration, software installation, and ongoing maintenance.1 This allows technical teams to focus exclusively on the logic of data engineering and validation. The architecture is a hybrid of traditional shared-disk and shared-nothing database designs, utilizing a central data repository for persisted data that remains accessible from all compute nodes within the platform.1 This tri-layered structure—comprising database storage, query processing (compute), and cloud services—forms the backbone of the Snowflake ecosystem.1
(To expand the sections below, click on the +)
The Storage Layer and Micro-Partitioning
When data is loaded into Snowflake, it undergoes an automated reorganization process into a proprietary, internally optimized, compressed, columnar format.1 This data is stored in cloud storage and is automatically divided into micro-partitions, which are contiguous units of storage.1 Each micro-partition contains between 50 MB and 500 MB of uncompressed data, and Snowflake stores metadata about the range of values for each column within these partitions.1 This metadata enables efficient "partition pruning," where the query engine skips irrelevant data during execution, a feature that significantly reduces input/output (I/O) overhead and compute costs.6
For data validation engineers, the implications of micro-partitioning are profound. Validation queries must be structured to align with the underlying data distribution to minimize scanning costs.8 When using QuerySurge to compare a source system with a Snowflake target, the alignment of join keys and filter predicates with Snowflake’s clustering keys ensures that the validation process remains performant even when handling billions of records.6
Multi-Cluster Compute and Elasticity
The query processing layer in Snowflake is powered by virtual warehouses, which are essentially clusters of compute resources.1 The separation of these warehouses from the storage layer allows for independent scaling.1 Virtual warehouses can be scaled up (vertically) to handle complex queries or scaled out (horizontally) to accommodate high concurrency.6 This elasticity is a vital asset for automated validation. Testing workloads, which are often resource-intensive, can be assigned to dedicated warehouses to ensure that production analytics are never compromised by the validation process.5
Scaling Dimension |
Technical Implementation |
Validation Benefit |
|---|---|---|
Vertical Scaling |
Increasing the size of a warehouse (e.g., Small to Large). |
Improves the performance of large, complex joins or aggregations required for deep data comparisons.6 |
Horizontal Scaling |
Adding clusters to a multicluster warehouse. |
Supports simultaneous execution of thousands of QueryPairs across multiple data subject areas.6 |
Manual Scaling |
Adjusting warehouse size based on predictable surges. |
Optimizes cost during scheduled nightly regression runs.6 |
Auto-scaling |
Dynamic adjustment based on real-time load. |
Ensures consistent throughput for continuous validation in CI/CD pipelines.6 |
Architectural Overview of QuerySurge
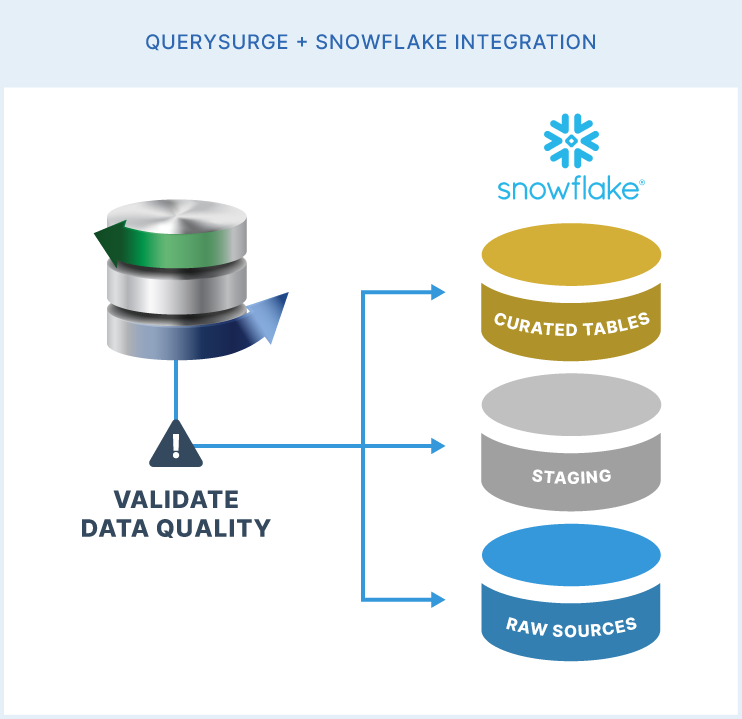
QuerySurge is an enterprise-grade, AI-driven platform specifically designed to automate data validation across the entire data pipeline, from raw ingestion to the final reporting layer.3 Its primary objective is to identify data mismatches, missing records, and transformation errors with surgical precision, ensuring that the global data supply chain remains intact.4 The platform’s architecture is built on a distributed model, utilizing agents to execute queries and compare result sets.9
Deployment Flexibility: Core vs. Cloud Models
QuerySurge provides two primary implementation paths: QuerySurge AI Cloud and QuerySurge AI Core.4 The choice between these models often depends on the organization’s security policies and infrastructure capabilities. The Cloud model is externally hosted and utilizes a cloud-based Large Language Model (LLM) for AI-driven test generation, offering minimal setup requirements and high speed.4 Conversely, the Core model is deployed on-premises within the organization’s network, ensuring that 100% of the data remains within local infrastructure—a critical requirement for highly regulated industries.4
Feature |
QuerySurge AI Cloud |
QuerySurge AI Core |
|---|---|---|
Deployment Type |
Externally hosted, cloud-based LLM.4 |
On-premises, local infrastructure.4 |
Infrastructure |
No local hardware required.4 |
Requires local server with GPU/CPU.4 |
Data Security |
Data processed in secure external environment.4 |
100% of data remains within the local network.4 |
100 Mappings Perf. |
~5 minutes 42 seconds.4 |
~6 minutes 28 seconds (on GPU).4 |
Primary Control |
Managed by QuerySurge.4 |
Full organizational control over security.4 |
The Role of QuerySurge Agents
The QuerySurge Agent is the workhorse of the platform, responsible for establishing connections to data stores, executing queries, receiving result sets, and packaging them for comparison.11 Because agents handle massive quantities of data, their hardware configuration is paramount to system performance.
For production environments, it is recommended that agents are installed on separate machines to avoid resource contention with the application server.10
The technical requirements for a production-grade agent include a minimum of 2 CPU cores and 8 GB of RAM, although larger deployments involving billions of rows may require significantly more memory to accommodate the JVM heap.10 The use of Solid-State Drives (SSD) is strongly preferred over standard Hard Disk Drives (HDD), as they can offer up to 10x faster performance during disk-intensive operations like data staging or result set exports.10
Engineering the Snowflake-QuerySurge Connection
The integration between QuerySurge and Snowflake is facilitated through Java Database Connectivity (JDBC), a standard interface that allows Java-based applications to interact with relational databases.5 Successfully establishing this bridge requires meticulous configuration of both the driver and the authentication parameters.
JDBC Driver Deployment and Agent Tuning
To connect to Snowflake, the snowflake-jdbc-x.x.x.jar must be downloaded and deployed to each QuerySurge Agent.12 For advanced security features, specifically key-pair authentication, the platform requires version 3.16 or higher of the JDBC driver.13 Once the driver is deployed, the QuerySurge Connection Wizard is used to define the Snowflake instance, including the account name (which may include region and cloud platform identifiers), login credentials, and the default warehouse, database, and schema.12
Beyond the basic connection, the agent must be tuned to handle the expected data volume. The major tuning parameters for a QuerySurge Agent are the heap size, the fetch size, and the message size.11 The heap size determines the amount of memory available to the JVM for processing result sets, while the fetch size controls the number of rows retrieved in each round-trip to the database.11 If the fetch size is set too high without a corresponding increase in heap size, the agent may encounter OutOfMemoryError conditions.11
Parameter |
Configuration Impact |
Technical Implication |
|---|---|---|
Agent Heap Size |
Increases memory for handling larger result sets.11 |
On 64-bit systems, the theoretical maximum is only limited by physical RAM.11 |
Fetch Size |
Controls the number of rows per JDBC trip.11 |
Larger fetch sizes reduce network round-trips but increase memory pressure.11 |
Message Size |
Chunks data for delivery to QuerySurge database.11 |
Default maximum is configured to stay below 50MB for database stability.11 |
query_tag |
Identifies sessions in Snowflake logs.14 |
Essential for auditing and cost attribution in multi-tenant environments.14 |
ocspFailOpen |
Manages certificate revocation checking.14 |
Can be set to true or false to balance security with connectivity reliability.14 |
Implementing Key-Pair Authentication
As organizations move toward zero-trust security architectures, traditional username/password authentication is being replaced by more secure methods like key-pair authentication. QuerySurge supports this through its Connection Extensibility feature, which bypasses the standard wizard in favor of a custom configuration.13
The technical workflow for key-pair authentication involves:
- Key Generation: Creating an RSA private and public key pair, with the public key assigned to the Snowflake user.
- Key Deployment: Placing the private key file in a secure, readable location on every machine hosting a QuerySurge Agent.13
- Path Formatting: When specifying the private_key_file path in the JDBC URL, forward-slashes must be used even on Windows environments, and the path should not contain spaces.13
- Security Libraries: In many cases, the agent’s JVM must be configured with the Bouncy Castle security provider to properly decrypt the private key. This is achieved by adding -Dnet.snowflake.jdbc.enableBouncyCastle=TRUE to the agent's Java options.13
- Parameterization: Appending the private_key_file and private_key_file_pwd (if the key is encrypted) to the JDBC connection string.13
Automated Validation Strategies for Snowflake Data
The true value of integrating QuerySurge with Snowflake lies in the ability to execute high-precision validation across complex data structures. Snowflake’s support for diverse data types necessitates a multi-faceted validation approach.1
(To expand the sections below, click on the +)
- Validating Semi-Structured and Nested Data
- Validating Slowly Changing Dimensions (SCD)
- Precision and Data Type Alignment
Validating Semi-Structured and Nested Data
One of Snowflake’s most distinctive features is its native handling of semi-structured data via the VARIANT, OBJECT, and ARRAY types.15 A VARIANT column can store any other data type, up to 128 MB of uncompressed data, and Snowflake automatically extracts as much of this data as possible into a columnar form for optimized querying.15
Validation of these hierarchical structures in QuerySurge often involves:
- Flattening: Using the FLATTEN function to convert nested arrays and objects into a relational format that can be easily compared against a source system.16
- Notation-Based Access: Utilizing colon notation (e.g., column:element) or bracket notation to extract specific keys for cell-level comparison.17
- Null Handling: Distinguishing between SQL NULL values and JSON null (VARIANT NULL), which Snowflake stores as a string containing the word "null" to preserve the structural information of the original file.15
Validating Slowly Changing Dimensions (SCD)
In the context of data warehousing, maintaining the integrity of Slowly Changing Dimensions (specifically SCD Type 2) is critical for historical reporting.2 QuerySurge has been proven in real-world scenarios to identify defects in SCD history that would be missed by simple row-count checks.2 For example, in a migration from Teradata to Snowflake, QuerySurge detected that 1.1% of records in a customer dimension had incorrect end dates due to a flawed date cast during the transformation process.2 Identifying such discrepancies at the row level ensures that the historical accuracy of the data warehouse is maintained.2
Precision and Data Type Alignment
Data validation often uncovers subtle discrepancies between source and target systems that arise from different handling of numeric precision. In a financial reporting context, QuerySurge has successfully identified rounding drifts when comparing Decimal(18,4) types in a source system against Float types in Snowflake.2 These "tiny" drifts can aggregate into significant discrepancies in enterprise-level financial statements, and QuerySurge’s ability to pinpoint these errors allows technical teams to adjust their type mapping and transformation logic to achieve exact parity.2
The DevOps for Data Paradigm
Modern data engineering teams are increasingly adopting DevOps practices—frequently termed "DataOps"—to accelerate the delivery of high-quality data.4 QuerySurge is a cornerstone of this movement, offering a "DevOps for Data" module that integrates validation directly into the CI/CD pipeline.3
RESTful API and Surgical Control
QuerySurge provides a comprehensive RESTful API with over 60 (and in some modules over 100) API calls, supported by full Swagger documentation.4 This architecture allows developers to automate the entire testing lifecycle:
- Test Generation: Utilizing AI-powered modules to convert data mapping documents into executable SQL QueryPairs.9
- Execution Orchestration: Triggering test suites automatically following an ELT job in Airflow, dbt, or Azure Data Factory.
- Quality Gates: Implementing logic within the CI/CD pipeline to block the promotion of code to production if a validation run fails to meet a defined success threshold (e.g., 99.9% match).4
Swagger-Powered Integration
The use of Swagger (OpenAPI) documentation is a critical benefit for engineering teams. It provides an interactive interface where developers can explore API endpoints, test calls in real-time, and view expected inputs and outputs without writing any code.19 This "try before you code" capability accelerates the integration of QuerySurge into existing deployment pipelines and eliminates the reliance on outdated static documentation.19
API Category |
Technical Capability |
Practical Application |
|---|---|---|
Execution |
Trigger tests, scenarios, or suites programmatically.22 |
Automated regression testing after every dbt model deployment.5 |
Configuration |
Dynamically update data store connections and user permissions.22 |
Managing test environments that scale up and down on demand.9 |
Reporting |
Retrieve pass/fail metrics and detailed mismatch reports.9 |
Exporting validation results to Jira or Azure DevOps for defect tracking.20 |
Analysis |
Access historical test data and trend metrics.25 |
Monitoring data reliability trends over time to identify systemic pipeline issues.26 |
Comparative Landscape: QuerySurge, dbt, and Great Expectations
In the Snowflake ecosystem, several tools are used for testing, but they often serve different and complementary purposes. Understanding the distinction between these tools is vital for building a comprehensive data trust stack.3
(To expand the sections below, click on the +)
The Water System Metaphor
To conceptualize the different roles of these tools, one can imagine a data pipeline as a water pumping and filtration system23:
- dbt (The Pumping System): Primarily focused on the transformation (the "T" in ELT). Dbt tests ensure that the "pipes" are connected correctly and that the transformation logic runs exactly as intended.23
- Great Expectations (The Quality Inspector): Acts as a tongue that tastes the water to ensure it is "drinkable." It measures the statistical quality of the data (e.g., ensuring an age column is between 0 and 120) and uses Python to handle complex, cross-field rules.23
- QuerySurge (The Lab Test): Performs a "forensic" row-by-row comparison between the raw source (the well) and the final target (the tap) to prove that "old equals new" and that no data was lost or corrupted during the journey.2
Strategic Differentiators
While dbt and Great Expectations excel at validating data within the warehouse, QuerySurge is the dominant solution for "deep ETL" layers and cross-platform validation.2 QuerySurge’s ability to connect to legacy NoSQL stores, flat files, and traditional relational databases while comparing them to Snowflake makes it the preferred tool for massive migrations.2
Feature |
QuerySurge |
dbt Tests |
Great Expectations |
|---|---|---|---|
Primary Focus |
Source-to Target / Migration.2 |
Transformation Logic.23 |
Data Quality/Observability.23 |
Language |
SQL-based QueryPairs.25 |
SQL / Jinja.23 |
Python-based Expectations.23 |
Connectivity |
200+ JDBC connectors.4 |
Native to SQL warehouse.23 |
Multiple backends (SQL, Spark, Pandas).27 |
Validation Level |
Row-level comparison.2 |
Schema/Rulebased.23 |
Statistical/Anomaly detection.27 |
Complexity |
High (Deep ETL specialists).24 |
Low-Medium (Analytics Engineers).23 |
Medium-High (Data Scientists/Engineers).23 |
Performance Engineering for Large-Scale Validation
Executing automated validation against billions of rows in Snowflake requires a rigorous approach to performance engineering. The goal is to maximize throughput while minimizing credit consumption.6
(To expand the sections below, click on the +)
Snowflake Query Optimization
Validation queries can be optimized by following several Snowflake best practices:
- Avoid SELECT *: Selecting only the columns required for the comparison reduces the amount of data scanned and transferred to the QuerySurge Agent.6
- Leverage Pruning: Using clustered columns in join predicates ensures that Snowflake can prune irrelevant micro-partitions.6
- Manage Spilling: Monitoring the Query Profile for local and remote spilling is essential. Remote spilling, where data overflows from memory and local disk to cloud storage, is a critical performance bottleneck that usually necessitates a larger virtual warehouse.6
- Query Caching: Snowflake’s result cache can be leveraged for recurring validation tests, although volatile functions like CURRENT_TIMESTAMP() should be avoided as they prevent the reuse of cached results.7
Parallelization and Concurrent Execution
Snowflake’s architecture is particularly well-suited for parallel ETL and validation.8 To reduce the end-toend processing time of a validation suite, teams should:
- Split Independent Workloads: Running multiple QueryPairs in parallel across a multi-cluster warehouse.8
- Utilize Multiple Warehouses: For massive pipelines, splitting sub-tasks across separate warehouses can be more efficient than running them sequentially on a single large warehouse.8
- Asynchronous Jobs: Leveraging Snowflake’s async job capabilities (often via the Snowpark Python API) to execute multiple SQL statements concurrently.29
Validating the "Last Mile": BI Report Testing
The validation of data pipelines is incomplete if the final presentation layer is ignored. Business decisions are made based on visualizations, not raw table rows.26 QuerySurge’s BI Tester module addresses this by validating that the data displayed in BI dashboards matches the underlying Snowflake data.9
BI Tester Capabilities
The BI Tester module provides a fully automated, no-code approach to validating reports in Power BI, Tableau, and other major platforms.30 It allows for:
- Regression Testing: Ensuring that version upgrades of the BI tool do not change the data output.30
- Migration Testing: Validating the consistency of reports when moving from one BI vendor to another (e.g., from Cognos to Power BI).30
- Metadata Validation: Querying and validating report metadata to ensure structural integrity.30
- Parameterization: Passing parameters to reports to test dynamic filtering and security views.30
This capability ensures that the entire "data trust stack" is verified, providing stakeholders with confidence that the analytics they see are an exact reflection of the verified data in Snowflake.3
Economic and Business Analysis
The adoption of automated validation is not merely a technical decision but a significant business investment with a measurable Return on Investment (ROI).3
(To expand the sections below, click on the +)
The Cost of Poor Data Quality
Research indicates that the average organization loses approximately $14.2 million annually due to poor data quality.4 Gartner estimates that 40% of business initiatives fail due to underlying data issues.4 For C-level executives making strategic "big bets" on the future of their firms, the lack of validated data is a fundamental risk to corporate governance and competitive advantage.4
ROI of Automated Testing
QuerySurge has been shown to deliver an 80% increase in testing speed compared to manual validation.3
In large-scale cloud migrations, this speed translates into:
- Near-Zero Defect Escape Rate: Continuous validation catches errors before they reach production, preventing costly re-work and operational delays.3
- Reduced Resource Costs: Automating the validation process allows QA engineers to focus on higher-value tasks and reduces the headcount required for manual data checking.20
- Faster Time-to-Market: Rapid validation enables faster releases in a DevOps environment, allowing organizations to realize the value of their data products sooner.5
Licensing and Total Cost of Ownership (TCO)
The cost of implementing QuerySurge depends on the selected licensing model and the required modules. Organizations can choose between Subscription (OPEX) and Perpetual (CAPEX) models, with pricing based on the number of Named or Floating users.31
License/Module |
Perpetual Price (Est.) |
Subscription Price (Annual) |
|---|---|---|
Full User (Named) |
$12,642 31 |
$6,006 31 |
Participant User |
$1,082 31 |
$514 31 |
BI Tester Module |
$9,665 31 |
$4,591 31 |
DevOps Module |
Included in Package 31 |
Included in Package 31 |
Setup Cost (5 hrs) |
$1,875 31 |
$1,875 31 |
Strategic Implementation Conclusions
The comprehensive analysis of Snowflake and QuerySurge integration reveals that automated data validation is an indispensable component of the modern data architecture. The separation of storage and compute in Snowflake provides the necessary performance foundation, while QuerySurge provides the forensic precision required to ensure integrity across billions of records.1
To achieve a "mature" data validation state, enterprises should adopt the following strategic priorities:
- Shift Left: Integrate validation into the development phase of the data pipeline, utilizing QuerySurge AI to generate tests as code is being written.6
- Continuous Validation: Embed QuerySurge into the CI/CD pipeline using its RESTful API to ensure that every code commit is automatically verified against the source data.4
- End-to-End Coverage: Expand validation beyond the warehouse to the BI reporting layer to ensure the "last mile" of data is trusted.9
- Performance Engineering: Right-size Snowflake warehouses and tune QuerySurge Agents (specifically JVM heap and fetch size) to handle the scale of modern data lakes without incurring unnecessary costs.6
By systematically addressing these areas, organizations can transform their data pipelines from fragile "black boxes" into robust, transparent, and trusted systems that drive confident business decisions and long-term value.4
Works cited
- Key concepts and architecture - Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/user-guide/intro-key-concepts - I test data warehouses. Here's what actually helped me sleep. - BaseNow, accessed March 4, 2026
https://www.basenow.com/i-test-data-warehouses-heres-what-actually-helped-me-sleep/ - Integrations | QuerySurge, accessed March 4, 2026
https://www.querysurge.com/solutions/integrations - White Papers - DataOps QuerySurge Enterprise Pipelines, accessed March 4, 2026
https://www.querysurge.com/resource-center/white-papers/dataops-querysurge-enterprise-pipelines - Snowflake - QuerySurge, accessed March 4, 2026
https://www.querysurge.com/solutions/integrations/snowflake - Performance - Snowflake, accessed March 4, 2026
https://www.snowflake.com/en/developers/guides/well-architected-framework-performance/ - 7 Snowflake Query Optimization Tips: Boost Performance and Reduce Costs, accessed March 4, 2026
https://seemoredata.io/blog/snowflake-query-optimization-tips/ - Snowflake Query Optimization 2025: Code Hacks & Examples - e6data, accessed March 4, 2026
https://www.e6data.com/query-and-cost-optimization-hub/snowflake-query-optimization - QuerySurge: Seven Proven Value Pillars, accessed March 4, 2026
https://www.querysurge.com/product-tour/seven-proven-value-pillars - QuerySurge System Requirements - Customer Support, accessed March 4, 2026
https://querysurge.zendesk.com/hc/en-us/articles/206127793-QuerySurge-System-Requirements - Tuning the QuerySurge Agent - Customer Support, accessed March 4, 2026
https://querysurge.zendesk.com/hc/en-us/articles/115000178066-Tuning-the-QuerySurge-Agent - Configuring Connections: Snowflake – Customer Support, accessed March 4, 2026
https://querysurge.zendesk.com/hc/en-us/articles/28337257757965-Configuring-Connections-Snowflake - Configuring Connections: Snowflake with Key-pair Authentication, accessed March 4, 2026
https://querysurge.zendesk.com/hc/en-us/articles/37442640351885-Configuring-Connections-Snowflake-with-Key-pair-Authentication - Configuring the JDBC Driver - Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/developer-guide/jdbc/jdbc-configure - Semi-structured data types | Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/sql-reference/data-types-semistructured - Considerations for semi-structured data stored in VARIANT | Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/user-guide/semistructured-considerations - Querying Semi-structured Data | Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/user-guide/querying-semistructured - Structured data types | Snowflake Documentation, accessed March 4, 2026
https://docs.snowflake.com/en/sql-reference/data-types-structured - Swagger API Documentation | QuerySurge, accessed March 4, 2026
https://www.querysurge.com/solutions/swagger-api-documentation - Technology | QuerySurge, accessed March 4, 2026
https://www.querysurge.com/industries/technology - QuerySurge - AI Training Business Profile, accessed March 4, 2026
https://www.querysurge.com/ai-training/querysurge_profile.html - Automating the Testing Effort - QuerySurge, accessed March 4, 2026
https://www.querysurge.com/business-challenges/automate-the-testing-effort - Great Expectations vs. dbt Tests: What's the Difference | DistantJob, accessed March 4, 2026
https://distantjob.com/blog/great-expectations-dbt/ - Qyrus Data Testing vs QuerySurge Data Testing, accessed March 4, 2026
https://www.qyrus.com/post/qyrus-data-testing-vs-querysurge-data-testing/ - QuerySurge Reviews 2026: Details, Pricing, & Features - G2, accessed March 4, 2026
https://www.g2.com/products/querysurge/reviews - Solving the Enterprise Data Validation Challenge - QuerySurge, accessed March 4, 2026
https://www.querysurge.com/business-challenges/solving-enterprise-data-validation - Why should I use Great Expectations if I already have tests in DBT? - Reddit, accessed March 4, 2026
https://www.reddit.com/r/dataengineering/comments/193eced/why_should_i_use_great_expectations_if_i_already/ - Best Data Pipeline Software in Japan of 2026 - Reviews & Comparison - SourceForge, accessed March 4, 2026
https://sourceforge.net/software/data-pipeline/japan/ - Query Parallelization in Snowflake | by Sabrina Liu - Medium, accessed March 4, 2026
https://sabrinazhengliu.medium.com/query-parallelization-in-snowflake-23207f917052 - QuerySurge BI Tester, accessed March 4, 2026
https://www.querysurge.com/solutions/querysurge-bi-tester - Licensing & Pricing Options - QuerySurge, accessed March 4, 2026
https://www.querysurge.com/product-tour/licensing-pricing-option



