QuerySurge DevOps for Data
See how to automate the validation and testing of your DataOps pipeline
Why automated data pipelines are no longer optional, and how QuerySurge leads the charge in data quality and velocity.
Before understanding the solution, we must quantify the problem. Manual testing and fragmented pipelines are costing enterprises billions.
To Prevent an Error
Estimated cost per organization due to poor data quality (Gartner).
Time Wasted
Of data scientists' time is spent cleaning and organizing data, not analyzing it.
Data Coverage
Typical coverage achieved by manual "stare and compare" testing methods.
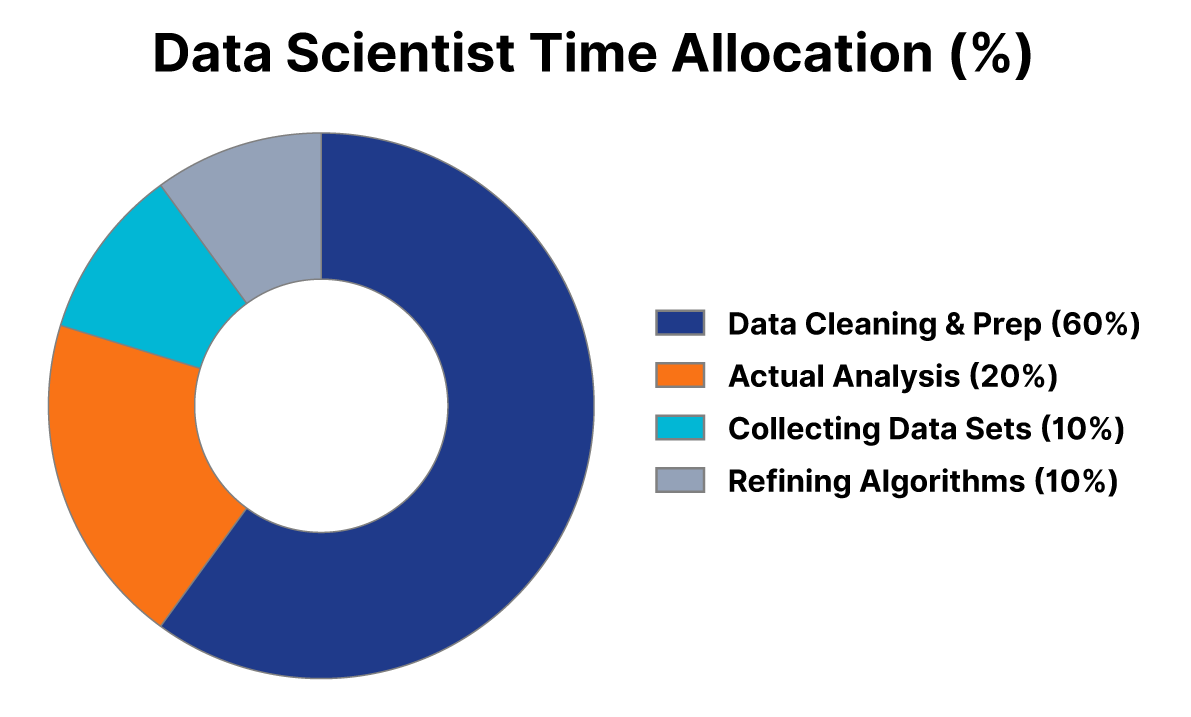
In traditional pipelines, highly paid data engineers and scientists function as data janitors. DataOps aims to invert this ratio by automating the mundane "cleaning" and validation tasks.
How QuerySurge integrates into the modern CI/CD pipeline to automate quality gates.
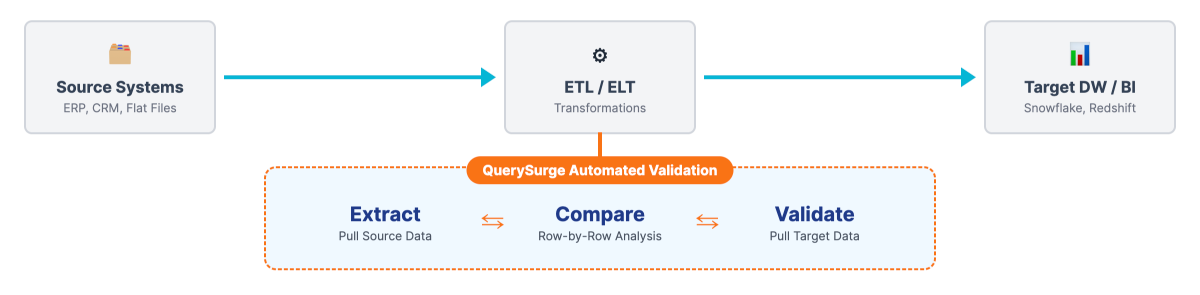
While legacy tools rely on sampling (checking 50 records out of 1 million), QuerySurge leverages a "Big Data" architecture to compare 100% of data points.
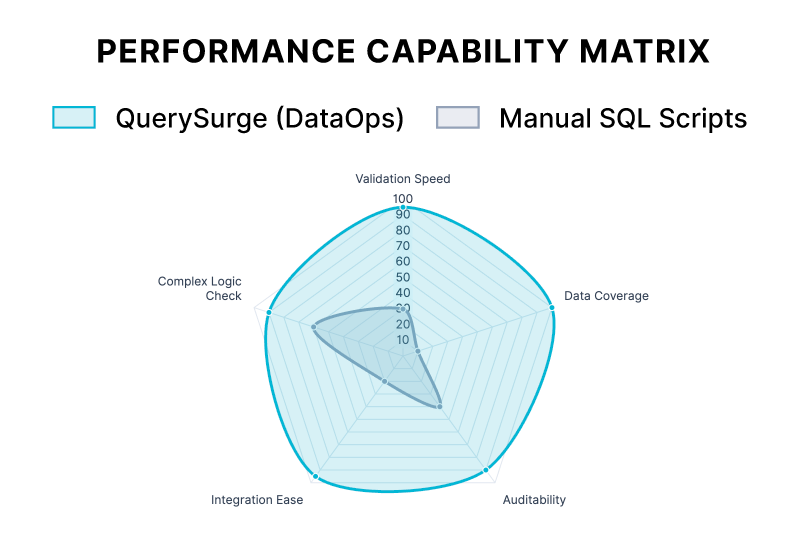
Implementing DataOps with QuerySurge doesn't just improve quality; it dramatically increases velocity. Teams catch defects early in the pipeline (Shift-Left Testing), preventing costly re-work.
Faster Validation
Risk Reduction
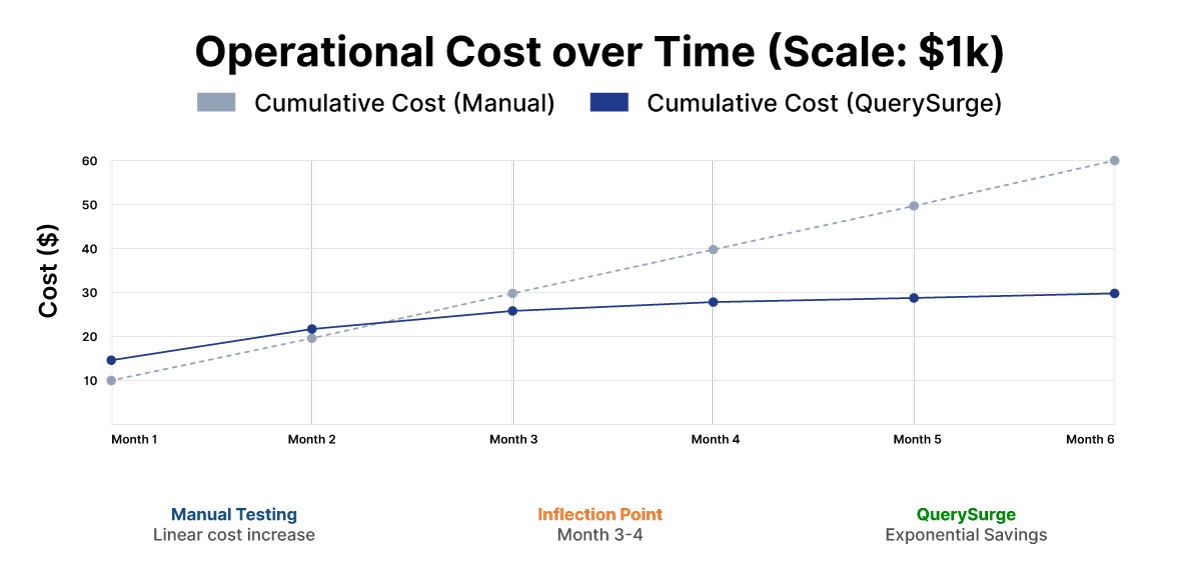
The initial setup of automated testing pays dividends rapidly as the number of data pipelines scales.
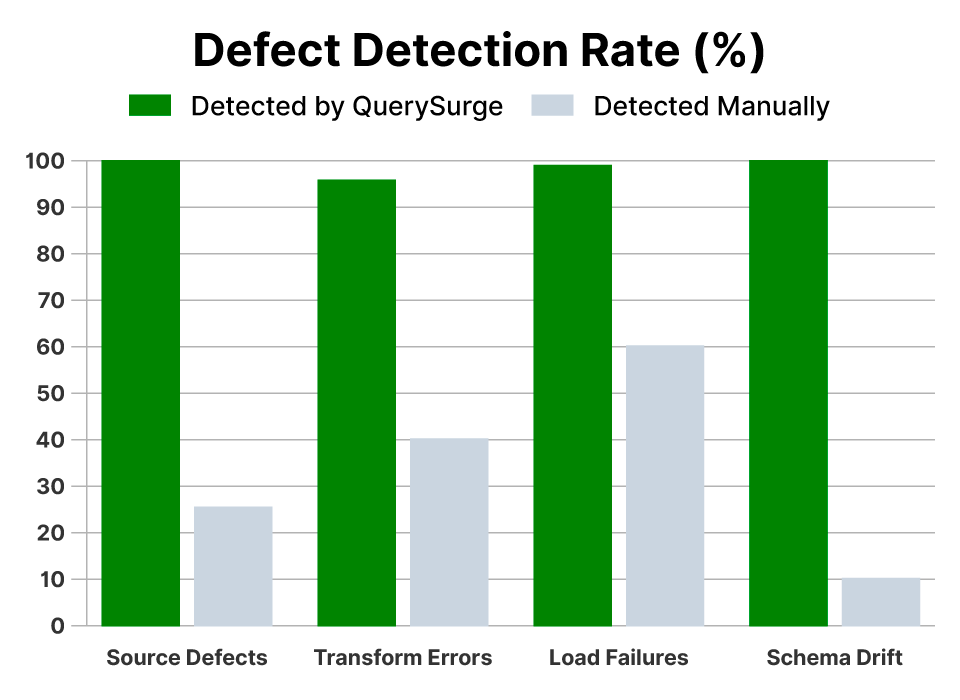
Enterprises leveraging DataOps strategies with QuerySurge report higher data trust, faster regulatory compliance, and significant reductions in operational data costs.